我们常常会思考什么样的数据才是大数据,只有数据量大才能真正称之为大数据吗?其实不然,大数据的特征应该包括数量、速度,多样性和精准性这四个方面,也就是通常所说的4个V: Volume,Velocity,Variety 和Veracity。如下图所示:
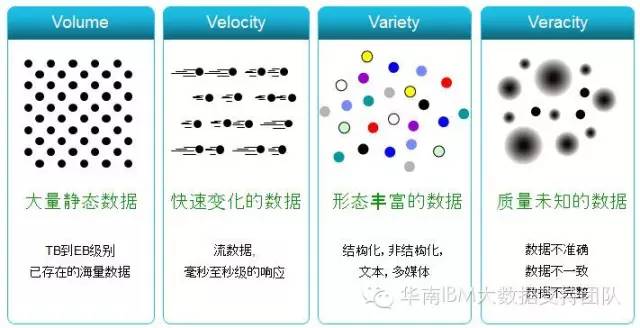
因此,数量大小只是描述大数据的其中一个维度,今天,我们不妨换个思路来聊聊大数据的另一个重要特征:Velocity(速度),看看如何将传统数据库中的数据快速、实时、准确地应用到大数据平台。快速获取,快速分析,快速应用,快速实现,从而帮助企业提升自身的竞争力并创造巨大的商业价值。
IBM 大数据产品介绍
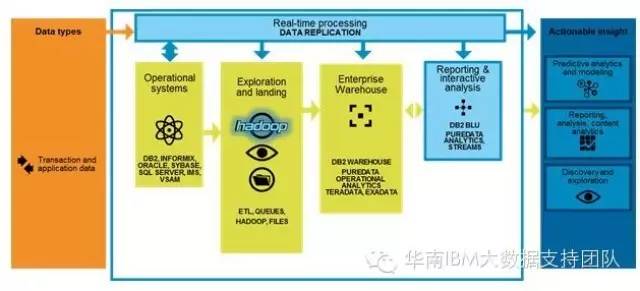
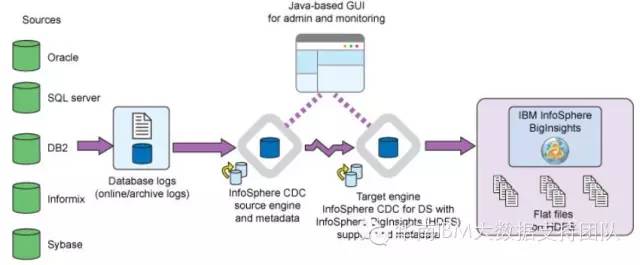
InfoSphere Change Data Capture(以下简称CDC)用于捕获源端交易数据库如DB2,Oracle的数据变化,并实时复制到目标数据库、消息队列、以及ETL解决方案(例如IBM InfoSphere DataStage)。
InfoSphere BigInsights由Hadoop分布式文件系统(HDFS)以及Pig,Hive,HBase和ZooKeeper等Hadoop生态系统子项目构成,用于分析和展现基于Apache Hadoop的海量数据。 接下来,我们将通过一个智能电表的应用案例来演示CDC如何将实时的增量数据复制到InfoSphere BigInsights的HDFS中。
系统架构
在下图所示的系统架构中,源端各种异构平台的传统数据库所产生的变化数据通过CDC的复制引擎源源不断的流向目标端 InfoSphere BigInsights 大数据平台,所有关系型结构化数据的实时更新都会以文件的形式或格式存储在HDFS文件系统中。
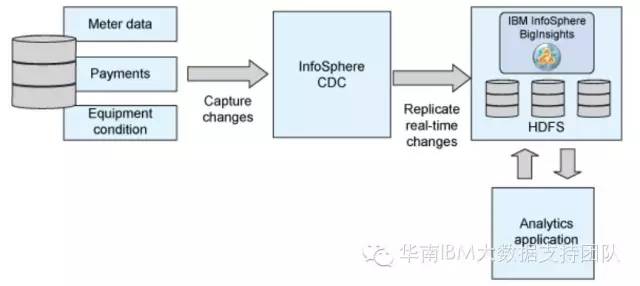
应用场景:智能电表系统
某公共事业公司利用智能仪表采集客户日常使用水,电,煤气等数据信息,这些信息的数据量庞大且实时变化快,通过分析这些仪表数据能及时了解客户的使用模式和习惯,以及费用开销。比如说该公司通过测量高峰期的用电量,能够收取更多的费用,能够设置客户用电的使用上限,可以创建激励机制让客户在特殊时段减少用电量等等。
该公司通过构建InfoSphere CDC + InfoSphere BigInsights的智能电表系统来实现以上这些业务功能,即CDC捕获电表系统的变化数据,并实时复制到BigInsights的HDFS文件系统,接着BigInsights对传送过来的实时海量数据进行复杂计算和模型分析,从而及时准确地响应了以上业务需求。
配置CDC到BigInsights(HDFS)的数据复制
安装并初始化InfoSphere BigInsights运行环境
1)首先,需要完成InfoSphere BigInsights的安装,安装完成后,Hadoop集群环境也随之搭建好了。然后,我们要确认环境变量是否设置正确
* CLASSPATH是否指向包含Hadoop核心Jar包的路径。
* HADOOP_CONF_DIR是否指向包含Hadoop配置文件的路径。
如果以上环境变量没有设置,我们也可以运行BigInsights自带的脚本程序biginsights-env.sh进行自动化设置,该脚本所在目录为
BigInsights_install_dir/conf.
2)缺省情况下,环境变量CLASSPATH仅包含Hadoop的核心JAR包hadoop-core-1.0.3.jar,我们还需添加以下JAR包到CLASSPATH中:
* commons-configuration-1.6.jar
* commons-logging-1.1.1.jar
* commons-lang-2.4.jar
这些JAR包路径为:BigInsights_install_dir/IHC/lib directory/

2. 启动InfoSphere BigInsights Hadoop集群中的HDFS组件
InfoSphere BigInsights本身已集成了很多Hadoop组件,例如Apache MapReduce, HDFS, Hive, Catalog, HBase, Oozie等等,这些服务可以通过InfoSphere BigInsights控制台或命令行启动。例如在Web浏览器中打开InfoSphere BigInsights管理控制台:
http://server:8080/data/html/index.html#redirect-welcome
然后,在管理控制台中选择并启动HDFS服务.
3. 安装InfoSphere CDC for InfoSphere BigInsights,
并在BigInsights中创建HDFS目录
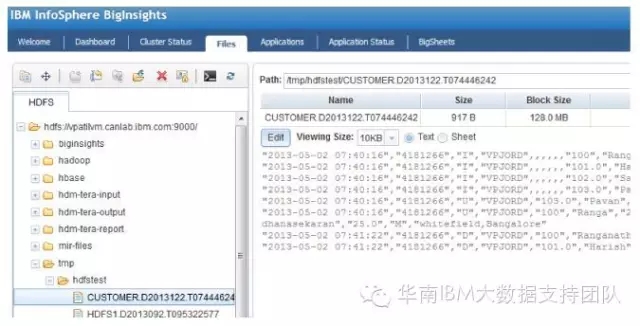
在InfoSphere BigInsights管理控制台中选中“Files”标签.
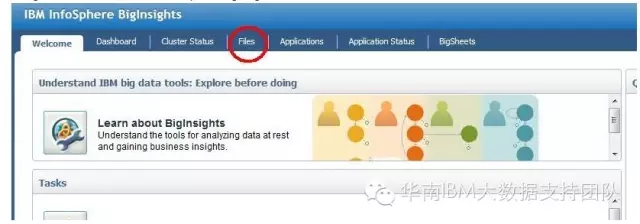
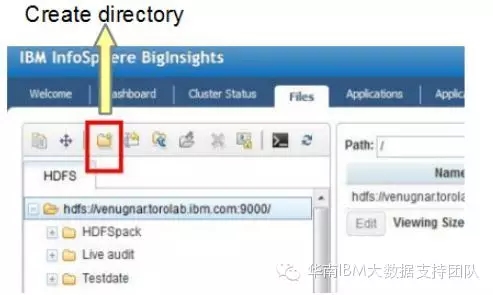
如下图所示,创建HDFS目录,用于写入CDC从源端数据库中捕获并复制过来的增量数据.
创建CDC实例
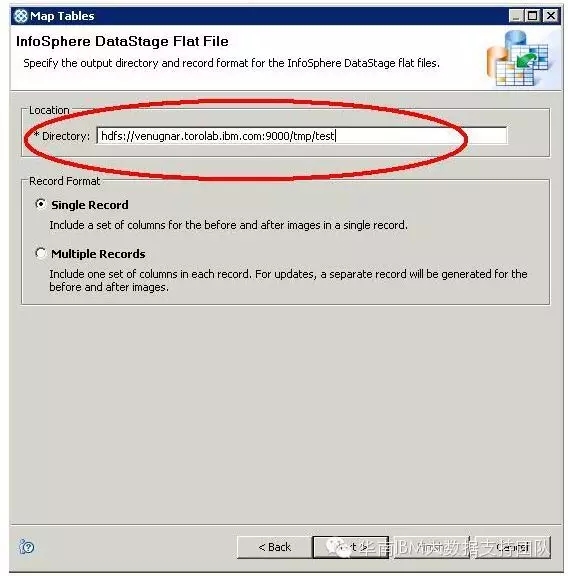
在CDC实例中创建预订(Subscription),并将源端数据库的表映射到刚刚已创建的HDFS目录中的某个文件。HDFS目录格式为:
hdfs://your-server:9000/目录名称/文件名
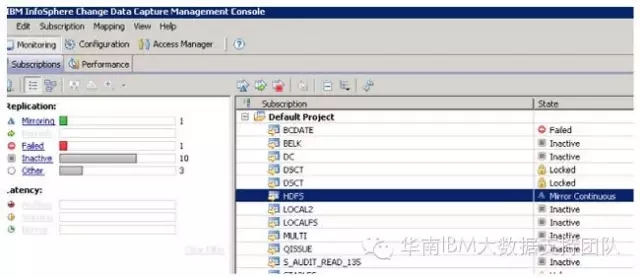
启动CDC复制数据并查看目标端所生成的HDFS文件
经过以上步骤,我们已完成了BigInsights和CDC的安装及配置,接下来便可启动CDC预订开始数据的实时复制了
当我们回到BigInsights的管理控制台,选中“File”标签,可以观察到在指定的HDFS目录路径下已生成从源端复制过来的增量数据。
可能有人会问,InfoSphere CDC 难道只能和IBM自家的大数据平台BigInsights集成吗?当然不是,CDC能提供对各大Hadoop厂商的广泛支持,例如:HortonWorks Data Platform(HDP),Cloudera CDH,Apache Hadoop等。
如果大家感兴趣的话,欢迎与我们联系!
慧都控件网年终促销最后一波,全场6折起,豪礼抢不停>>>
截止时间:2016年12月31日
更多大数据与分析相关行业资讯、解决方案、案例、教程等请点击查看>>>
详情请咨询在线客服!
客服热线:023-66090381


