简介
数据挖掘使专家、分析师和用户可以洞察大量数据集中存在的模式,并使之成为日常业务流程中的一部分。在过去,数据挖掘一直是统计和数据分析专家的任务。另一方面,数据挖掘的结果又常常与公司中各种不同的用户有关联。
考虑以下场景。您收集关于符合特定的人口特征(例如年龄、职业和居住地点)的客户以及过去的事务(例如售出的产品以及合同)的数据。商场营销部门希望针对具有相似特点的特定客户群开发新的定制产品。如何发现那样的独特用户群?数据集群为这个问题提供了一个解决方案。它自动根据数据集的属性或特征对数据集进行分组。然后,分析师查看这些组,并交互式地对它们进行微调,直到满足他/她的需要。而市场营销专家将发现,有一群为数不多、但是在经济上有重大意义的客户,他们的年龄超出了平均年龄,不使用 Internet 银行。根据这样的信息,可以为这些客户开发专门的产品。在分析过程中,一个关键的步骤就是让用户理解数据集群步骤的结果。专业的分析师通常并不擅长低级的数据库编程。
如何将数据挖掘的结果交付给需要它的分析师和雇员?如何显示结果,以反映用户所涉及的业务流程?如何满足安全性需求,使每个用户只看到他/她应该看到的内容。对于这些问题,要想给出令人满意的答案,必须将视角从统计分析转变到实际的终端用户以及他/她所涉及的业务流程上来。InfoSphere Warehouse 是企业数据仓库的强有力的基础。InfoSphere Warehouse 直接在存储数据的底层 DB2 数据库中提供数据挖掘功能。整个数据挖掘功能可以通过一个容易使用的、基于 Eclipse 的工具平台来访问,而且部署任务可以直接在工具中触发。
IBM Cognos 是报告解决方案中的领先者之一。在很多公司中,报告扮演着一个重要的角色,因为它有助于以不同的方式为不同的目标人群合并和可视化相关信息。报告的结果通常是通过对存储在数据仓库中的信息应用基本的算术运算而得到的(例如,每月的平均销售额)。对于高级的分析,例如上面的例子,则超出了报告框架的范围和能力。因此,可以将两者相结合,既使用 InfoSphere Warehouse 的可伸缩的、高级的分析功能,又使用 IBM Cognos 已有的、先进的报告功能。接下来的小节展示如何灵活地将 IBM InfoSphere Warehouse Data Mining 与 IBM Cognos 相结合,以实现这个目标。这种集成不需要任何复杂的编程或设置,只需使用纯 DB2 SQL 就能完成。
接下来的小节简要地介绍 InfoSphere Warehouse 和 IBM Cognos 的基本架构。然后将描述如何集成它们。最后,通过一个简单的、逐步讲解的来自医疗保健领域的例子来演示这种集成。这个系列接下来的文章将描述这种集成的一些更高级的技巧和概念。
产品组件
IBM InfoSphere Warehouse
InfoSphere Warehouse 以 DB2 作为数据存储。它提供了数据库分区功能(DPF),以便以可伸缩的、安全的、高性能的方式存储数据仓库中的数据,并将在线事务处理(OLTP)数据库的优点与大型数据仓库的存储需求相结合。InfoSphere Warehouse 提供了很多不同的用于仓库管理和分析的工具。这些分析组件有:
- Cubing 服务
- 数据挖掘
- 文本分析
InfoSphere Warehouse Design Studio 是基于 Eclipse 的工具平台,用于为数据挖掘和文本分析设计工作负载规则、数据转换流和分析流。然后,可以将这些流部署到 InfoSphere Warehouse 管理控制台,以根据需要进行调度和运行。InfoSphere Warehouse 数据挖掘是用 DB2 存储过程和用户定义函数构建的,以利用 DB2 作为执行环境,从而获得高性能的数据库内执行。可以通过 SQL 接口或通过 InfoSphere Warehouse 的挖掘流访问它。
数据挖掘是一项从大型数据集中发现有用信息的任务。一个典型的场景是医疗保健,本文将用它作为实例。如今可以收集到大量的卫生保健数据,这些数据描述很多不同的病人数年来的状态。这种数据的一个重要用途是在早期发现潜伏性疾病的指标。例如,出于这个目的,可以收集患有心脏病的病人的数据,并分析什么因素与这种疾病有关,例如血压和体重。这种数据必须在收集后进行转换,使之能用于数据挖掘。更具体而言,需要有一个表,每个病人对应于其中的一行记录,表中有一些列,表示关于病人的信息。而且,还应该有一个专门的列表明这个病人是否真正患病。图 1 显示了一种可能的模式:
图 1. 心脏病数据库表的模式(InfoSphere Warehouse 例子的一部分)
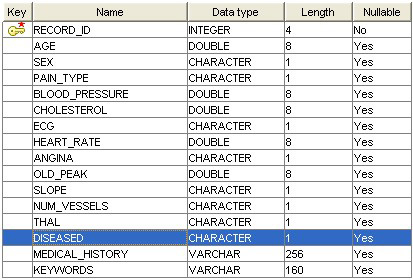
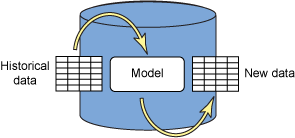
基于这种数据,InfoSphere Warehouse 中的存储过程可以构建一个模型,对于任何新的病人,该模型可以预测他/她是否可能有潜伏性心脏病。这个过程称作 “建模”。这样得到的 XML 数据挖掘模型存储在数据库中,可以通过 SQL/XQuery 进行访问。这个模型可用于两个目的:首先,可以从这个模型提取信息,以洞察哪些是心脏病的重要指标以及其他统计信息。其次,可以将该模型自动应用到新的数据记录上。因此,对于在心脏病这一列上还没有值的任何记录,可以自动添加这个值,另外再添加一个表示预测的置信度的一个值。这个过程称作 “评价”。图 2 通过示意图显示了这个过程:
图 2. 基于历史数据构建预测模型,然后将此模型应用到新数据上
InfoSphere Warehouse 几乎包含目前所有数据挖掘算法的极为高效的实现。要调用数据挖掘,首先要将数据写到一个表中。然后创建一个模型,再将这个模型应用到目标值尚且未知的记录上,以产生一个预测和该预测的置信度值。所有数据挖掘函数都是作为常规的 SQL 命令来调用的,后面您将看到这一点。这样便很容易集成到几乎所有的设置中,例如 Web 服务。
IBM Cognos 11 Business Intelligence
IBM Cognos 11 Business Intelligence 提供一套完整的商业智能(BI)功能,并且基于一个灵活的面向服务架构(SOA)。它的主要功能有报告、分析、指示板(dashboard)和计分卡(scorecarding)。
报告用于聚合关于业务流程的相关数据,并将它分发给最能从这种特定信息中受益的人。在数据挖掘环境中,这意味着将结果传递给最能从生成的业务洞察力中受益的人。
创建和发布业务报告所需的 Cognos 8 组件有:
- Cognos Connection:Cognos 11 功能的 Web 门户和入口点。用户可以从这里管理、组织和查看已有的内容,例如报告或指示板。可以从 Cognos Connection 启动基于 Web 的 authoring studio,例如 Report Studio,以创建新的资源或编辑已有的资源。它还可以用于管理 Cognos 服务器,例如更改访问限制、导入内容或者更改将一份报告发送给哪些人的列表。
- Cognos Framework Manager:用于 Cognos 11 中使用的数据源的建模工具。例如,在 Cognos 报告中,可以通过在 Framework Manager 中描述一个元数据层,来访问大多数数据库和其他数据源,例如 Web 服务中的数据。可以将数据库表、视图和存储过程作为查询主题添加到 Cognos 包中。Framework Manager 用于导入和合并公司中不同数据源中的信息,以便在 Report Studio 等的 Cognos 11 BI 工具中以一致的方式使用该信息。需要特别注意的是,创建报告时,数据本身还是存放在数据源中,并在那里被访问。
- Cognos Report Studio:Cognos 11 BI 中的一个基于 Web 的 authoring studio。它用于创建和编辑关于 Framework Manager 中描述的数据的高级报告。它提供了一些强大的功能,例如下钻(drill-down)、提示和丰富的图表库。
要将这种数据放入报告中,需要执行两个步骤:
- 在 Framework Manager,数据建模者创建 Cognos 元数据,这种元数据从业务的角度描述数据库中的数据(包括表之间的关系、值的业务名称等)。
- 创建好元数据后,将它作为一个包部署到 Cognos 8 内容存储中。然后可以通过 Cognos Connection 和 authoring studio 从这里访问它。
- 报告设计者进入 Cognos Connection,并在部署的包上创建一个新报告。创建报告后,可以管理目标组和分发形式(例如 email 或 Web 门户)。
能够从关系数据源创建报告是 InfoSphere Warehouse 数据挖掘与 IBM Cognos 集成的关键。
集成架构
如前所述,Cognos 报告的内容由一个关系数据源交付的一个结果集组成。一个特定报告的内容由针对一个或多个数据源的一个(动态的)SQL 查询决定。可以通过以下方式,利用这个基本的通信模式将数据挖掘与 Cognos 报告集成:
- Cognos 可以显示有评价信息的表,还可能一起显示置信度信息。
- Cognos 可用于显示模型信息。该信息是通过表提取器函数或 XQuery 查询从实际的 XML 模型中提取的。
- Cognos 可以通过调用 SQL 存储过程来动态地调用数据挖掘和评价。这样便允许:
- 在报告界面中以用户提供的不同设置调用数据挖掘
- 在数据的不同子集上调用数据挖掘(例如,创建递归下钻报告)
- 根据用户的输入动态地进行记录
图 3 总结了所有这些案例中使用的调用模式。
图 3. IBM InfoSphere 数据挖掘与 IBM Cognos 报告的基本集成架构
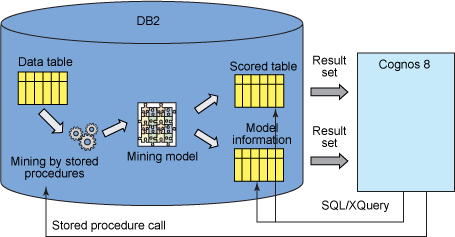
可以通过一个存储过程调用来调用数据挖掘,数据挖掘将在数据库中创建一个 XML 挖掘模型。可以根据新的数据记录这个模型,或者将模型信息提取到一个表中。然后,Cognos 可以使用这些表。从 Cognos 报告中,用户可以通过调用数据库上相应的存储过程,交互式地调用数据挖掘。
这种集成带来了很多好处:
- 它非常简单,只需要 SQL 方面的知识,而不需要附加的编程。
- 挖掘模型存储在数据库中,可以从 Cognos 中安全、有效地访问它们。
- 通过使用存储过程,可以从 Cognos 中触发和控制整个数据挖掘过程。
接下来的小节是这种集成的一个逐步讲解的例子,这也是最简单的例子:对数据库中的记录进行评价,并将结果显示在一个 Cognos 报告中。模型信息的提取和从 Cognos 中对数据挖掘的动态调用将在本系列接下来的文章中谈到。
在 Cognos 报告中使用数据挖掘结果:卫生保健部门的一个例子
这个例子分析一家医院的病人数据。这家医院的心脏科有他们的病人的主记录,以及一些度量指标,例如心率、血压、胆固醇等。这家医院针对四种不同的心脏病对病人进行检查。病人的记录中有一个列表明他们是否患有四种心脏病之一,y 表示是,n 表示否。图 1 中描绘了相应的心脏病数据库表。这个表可以在 InfoSphere Warehouse 附带的例子中找到。
分析的目标是预测新的病人患上这四种心脏病之一的风险。如果风险较高,则应该立即进行体检。
这里启用了风险管理,虽然没有针对这四种心脏病之一做过专门的检查,但是已经从一些早期的在其他地方做的体检得到度量指标。
创建预测模型
首先,基于 HEART 表创建一个预测模型,通过该模型可以预测病人患上心脏病的风险。
创建一个 Data Warehouse 项目:
右键单击 Project Explorer,并选择 New > Data Warehouse Project(如下面的图 4 所示)。
图 4. 创建一个 Data Warehouse 项目
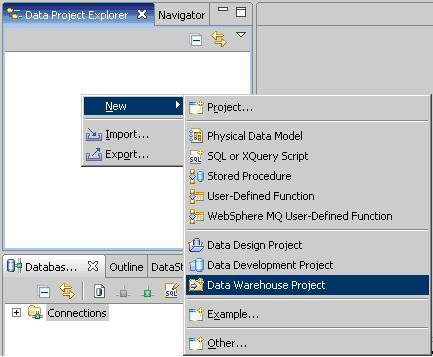
在接下来的向导中,输入项目名称,例如:AdvancedAnalytics。然后单击 Finish。
创建一个空的挖掘流:
- 展开新创建的项目。
- 右键单击文件夹 Mining Flows,并选择 New > Mining Flow。
- 在出现的向导中,输入挖掘流的名称 Heart Disease Risk。
- 在这个例子中,您将使用数据库。因此,保留默认设置,单击 Next。
- 选择 DWESAMP 数据库,并单击 Finish。
创建挖掘流:
这时会打开 Mining Flow 编辑器。在挖掘编辑器的右侧可以看到一个面板,其中有一些操作符(见图 5)。可以通过将这些操作符拖放到编辑器画布上来构建一个挖掘流。
图 5. Design Studio 中的挖掘流
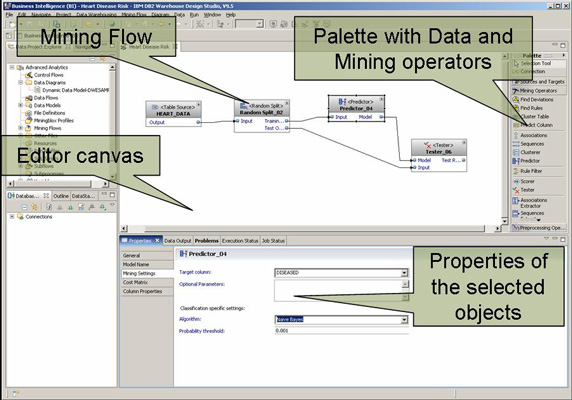
为了创建用于预测病人患病风险的挖掘模型,可遵循以下步骤:
- 在面板中,从 Sources and Targets 区中选择一个 Table Source 操作符,将它拖到编辑器上。
- 在表选择对话框中,展开 HEALTHCARE 模式并选择 HEART 表,然后单击 Finish。
- 在面板中,从 Preprocessing Operators 区中选择一个 Random Split 操作符并将它拖到编辑器上。
- 通过拖动鼠标,将第一个操作符的 Output 端连接到第二个操作符的 Input 端。
- 选择 Random Split 操作符。
- 在挖掘编辑器下面的 Properties 选项卡中,将测试数据属性 Percentage 设为 20。这意味着之后我们将使用 20% 的数据来验证我们的模型。因此,在构建预测模型之前,必须先划分数据。
- 在面板中,从 Mining Operators 区选择一个 Predictor 操作符并将它拖到编辑器上。
- 将 split 操作符的 Training Output 端与 Predictor Input Port 相连。
- 选择 Predictor 操作符。
- 在挖掘编辑器下面的 Properties 选项卡中,选择左边的 Mining Settings 选项卡。
- 在 Target column 选择列表中,选择 DISEASED 作为要预测的列。
- Design Studio 自动识别出您要预测一个标称值列,并自动提供可用于这一目的设置(在同一个选项卡中)。在 Algorithm 选择列表中,选择 Naïve Bayes。
- 在 Mining Settings properties 选项卡上,选择 Model Name 选项卡。保留前缀,但是将模型名称改为 HeartDiseasePrediction。
- 另外,从面板中的 Mining 区选择 Tester 操作符,并将它拖到编辑器上。
- 将 Predictor 的 Model output 端与 Tester 的 Model input 端相连,再将 Random Split 的 Test output 端与 Tester 的 input 端相连。
- 保存挖掘流,例如单击编辑器区并按 Ctrl+S。
现在,挖掘流已经可以执行了。
执行挖掘流:
可以执行整个挖掘流编辑器,或者通过右键单击一个操作符并选择 Run to this step… 只执行挖掘流中特定的路径。在这个场景中,右键单击 Tester 操作符,选择 Run to this step…,然后单击 Finish。这个流生成一个模型,该模型预测患上心脏病的风险,并将它存储在数据库中。先在 80% 的数据上对它进行训练,然后在剩下的数据上对它进行测试。这样可以估计该模型在新数据上执行的效果。这里只需右键单击 Tester 操作符的 Test Result 端。您也可以看看模型本身。为此,右键单击 Predictor 操作符的 Model 端。
使用挖掘模型对新数据进行评价
评价是指将之前经过学习的模型应用到新数据上。新的数据没有分类别(这里是指还没有做过心脏病检查),评价过程根据挖掘模型将一个预测赋给每个新的记录。
为评价创建一个新的挖掘流:
执行与创建新的挖掘流中相同的步骤,但是为它提供另一个名称,例如 Classify New Patients。
创建评价流:
为了创建用于对新病人分类的评价流,可执行以下步骤:
- 在面板中,从 Sources and Targets 区选择一个 Model Source 操作符并将它拖到编辑器上。
- 在挖掘模型选择对话框中,展开 classification 模型,并选择 AdvancedAnalytics.HeartDiseasePrediction 模型。
- 从面板的 Sources and Targets 区中将一个 Table Source 操作符拖到编辑器上。
- 在表选择对话框中,展开 HEALTHCARE 模式并选择 HEART 表。可以每晚将这个表装载到仓库中,或者每当有新的病人来医院,并且有必要的度量指标时实时地将这个表装载到仓库中。
- 从面板的 Mining Operators 区中将一个 Scorer 操作符拖到编辑器上。
- 将模型和 table source 操作符连接到 scorer。
- scorer 附加 2 个列,其中一个列包含类别(y 和 n),另一个列指定这个类别的确定性。为了存储这个有评价信息的表,必须以 Table Target 操作符的形式创建一个包含这些列的适当的表。
为此,右键单击 scorer 的输出端,并选择 Create Suitable Table…。 - 在出现的对话框中,指定新表的名称:NEW_PATIENT_CLASSIFICATION,以及将在其中创建这个表的模式:HEALTHCARE。 单击 Finish。
- 保存评价流。
- 最后,通过右键单击 table target 操作符并选择 run to this step,执行这个流。
执行这个流后,下方的视图会显示有评价信息的表中的示例数据(见图 6)。如果向右滚动,可以看到 scorer 添加的两个列。
图 6. 有示例结果的评价流
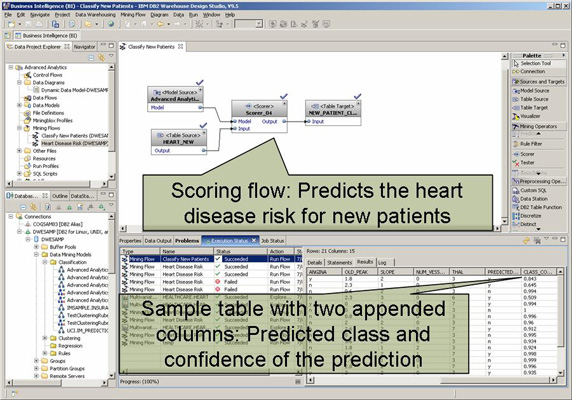
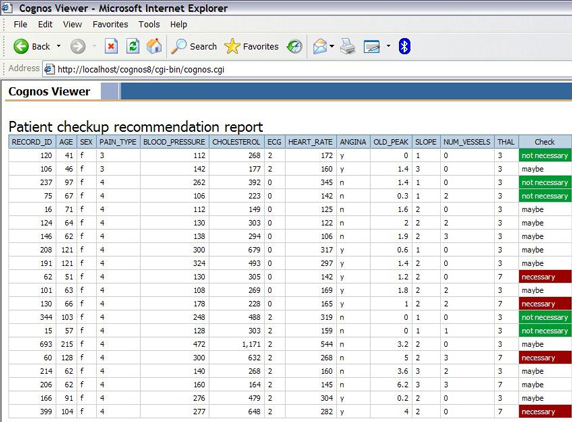
第一个附加的列 PREDICTED_CLASS 包含预测。它表明挖掘模型将当前病人归为哪种类型,将患上(y)还是不会患上(n)这种病。第二个附加的列 CLASS_CONFIDENCE 包含介于 0 到 1 之间的数字,它表明 scorer(根据模型)对于预测有多大的确定性。1 表示 “100% 确信预测的类别是正确的”。
在 Cognos Framework Manager 中创建元数据
在使用挖掘结果创建报告之前,需要定义应该使用哪些资源(数据库、表或视图???。Framework Manager 还允许通过定义连接和新列(用表达式)来增加数据源。
这个简单的例子创建一个 Cognos Framework Manager 报告。定义有评价信息的结果表,并发布元数据。
打开 Framework Manager 并创建一个新项目:
- 可以从桌面启动 Cognos Framework Manager。
- 启动后,单击 Create a new project…。
- 在出现的对话框中,指定名称 HeartMetaData,并单击 OK。
- 选择 English 作为语言,并按 OK 按钮。
- 由于要从一个 DB2 表创建元数据,所以选择一个常见的 Data Sources,并单击 Next。
- 选择 DWESAMP 数据库, 并单击 Next。
- 现在需要选择要导入为元数据的数据对象。展开 HEALTHCARE 模式和 table 文件夹,选择在评价流执行期间创建的 NEW_PATIENT_CLASSIFICATION 表。单击 Next。
- 这个页面上的设置就完成了,单击 Import,然后单击 Finish。
图 7. Cognos 8 Framework Manager
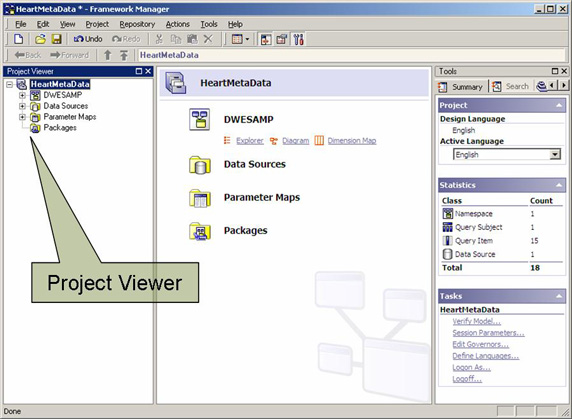
在 Project Viewer 的左侧,可以浏览新创建的项目。现在,定义一个附加列,以组合评价流创建的 2 个预测列的洞察力。其思想是以一种容易理解的方式为医生提供挖掘出的洞察力。
为此,执行以下步骤:
- 展开 DWESAMP。可以看到评价流中创建的表 NEW_PATIENT_CLASSIFICATION。
- 双击该表。
- 这时出现 Query Subject Definition 对话框。进入 Calculations 选项卡(见图 8)。
图 8. Query Subject Definition 对话框
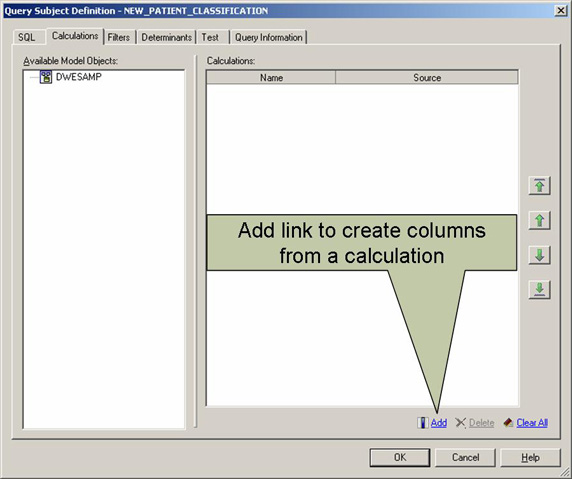
- 单击 Add 创建一个通过一个计算定义的新列。这时出现 Calculation Definition 对话框。
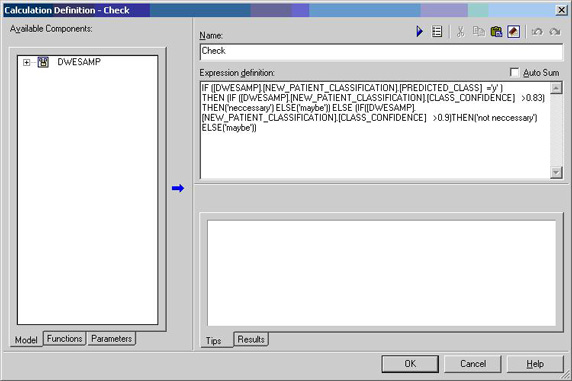
- 在 name 域中输入 Check,并在 Expression definition 文本域中输入以下表达式(在桌面上的 Calculation Definition.txt 文件中也可以找到这个表达式):
IF ( [DWESAMP].[NEW_PATIENT_CLASSIFICATION].[PREDICTED_CLASS] = 'y') THEN (IF ([DWESAMP].[NEW_PATIENT_CLASSIFICATION].[CLASS_CONFIDENCE]>0.83) THEN('necessary') ELSE('maybe')) ELSE (IF([DWESAMP].[NEW_PATIENT_CLASSIFICATION].[CLASS_CONFIDENCE] > 0.9) THEN('not necessary') ELSE('maybe'))
上面的表达式根据 PREDICTED_CLASS(y 和 n)和 CLASS_CONFIDENCE 创建 3 个新的类别。该表达式将预测类别为 y 且相应的置信度超过 83% 的病人定义为高风险病人(意味着需要体检)。而预测类别为 n 且相应置信度超过 90% 的病人则属于低风险病人(意味着不必做体检)。其他病人归类为中等风险(可能需要体检)。图 9 是 Calculation Definition 对话框的一个例子。图 9. Calculation Definition 对话框
- 单击 OK 关闭 Calculation Definition 对话框。
- 可以通过进入 Test 选项卡并单击 Test Sample 测试这个表达式。
- 单击 OK 关闭 Query Subject Definition 对话框。
创建一个包并发布它:
- 为了使新创建的元数据可被使用,进入 Project Viewer 并右键单击 Packages 文件夹,然后选择 Create > Package。
- 在 name 域中,输入 Heart,并单击 Next。
- 直接单击 Next,因为不用做其他事情。
- 在接下来的对话框中,将 DB2 添加到 Available function sets 列表中,然后单击 Finish。
- 在接下来的对话框中,单击 Yes 继续发布过程。
- 在 Publish 向导的 Select publish location 部分,单击 Next,因为不需要更改什么。
- 这个例子中不必指定安全设置。因此,单击 Next。
- 然后按下 “Publish” 按钮。
- 在提示您已成功地发布包的对话框中,单击 Finish。
创建一个简单的 Cognos 挖掘报告
Cognos Report Studio 是一个完全基于 Web 的应用程序。可以通过从桌面双击 Internet Explorer 图标(左上角)启动 Report Studio。
为创建一个简单的挖掘报告,必须执行以下步骤:
- 在 Welcome 屏幕上,单击 Create professional reports。
- 在 Select a package 浏览器中,单击您在 Framework Manager 中发布的 Heart 包。
- 在 Welcome 对话框中,单击 Create a new report or template。
- 选择空白模板,然后单击 OK。
- 在 Insertable Objects 面板中,可以在不同的选项卡之间进行选择。这里选择 source(Data sources)选项卡。在将数据添加到报告之前,需要一个布局结构。可以从 Toolbox 选项卡得到布局结构,所以现在进入该选项卡。
图 10. Report Studio
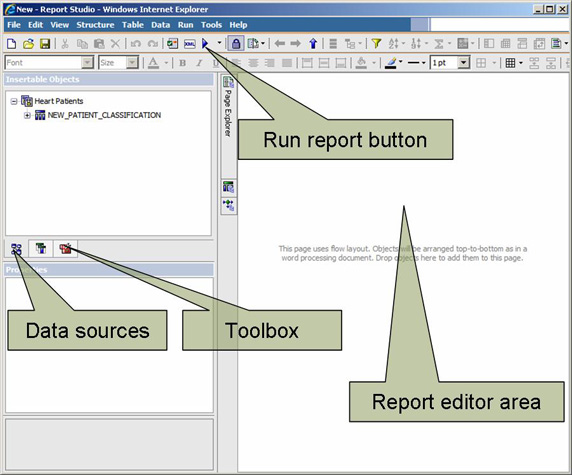
- 从显示的对象列表中,将一个 Text Item 拖到报告编辑器区(见图 10)。
- 在文本框中,输入名称 Patient checkup recommendation report。
- 在工具箱中找到 List 项,并将它拖到编辑器区。
- 回到 Source 选项卡(Data sources),将 NEW_PATIENT_CLASSIFICATION 表拖到编辑器区中的列表中。
- 可以看到经过分类的病人表,如果向右滚动,还可以看到附加的列。由于只需要在 Framework Manager 中创建的附加列 Check,所以去掉另外两个列 <PREDICTED_CLASS> 和 <CLASS_CONFIDENCE>。选择这两个列的列标题(按住 Ctrl),在选择的标题上单击右键,并从上下文菜单中选择 Delete。对于当前的例子,还要移除列 <DISEASED>、<KEYWORDS> 和 <MEDICAL_HISTORY>。
- 现在,需要用绿色突出显示那些不需要体检(not necessary)的病人,用红色突出显示需要体检(necessary)的病人,其他人(maybe)则不突出显示。为此,右键单击 Check 列(注意:单击列的主体,而不是标题),并选择 Style > Conditional styles…。
- 在 Conditional Styles 对话框上,单击左下角的图标,创建一个新的条件样式。
- 在接下来的对话框中,Check 列已经被选中。从 Type of conditional style 下拉列表中,选择 String,并单击 OK。
- 在接下来的对话框中,单击左下角的图标,并选择 Select Multiple Values…。 Report Studio 直接从数据库获取可能的值(注意:Report Studio 可能要求提供 DB2 用户 ID 和密码)。
- 首先将值 necessary 添加到选择的列表中,并单击 OK。
- 重复步骤 14 到 15,添加值 not necessary。
- 对于值 not necessary,从 Style 下拉列表中选择 Excellent。
- 对于值 necessary,从 Style 下拉列表中选择 Poor。
- 连续两次单击 OK。
- 选择标题,单击 Properties 面板上的 Font 弹出菜单,更改标题的样式。
- 单击 Run report 按钮查看产生的报告。
图 11 显示最后的报告。最右边的列显示风险类别。
图 11. 心脏病风险报告
结束语
本文描述了可以将 InfoSphere 数据挖掘简单地集成到 Cognos 报告中的基本架构。集成对于接受数据挖掘有重要的影响,因为结果的使用者不必知道关于挖掘过程的任何细节。本文提供了源于卫生保健部门的一个实用的例子,这个例子展示了如何通过很少的开发实现简单的集成。
除此之外,还有其他可能性。接下来的文章将讨论一些更高级的话题,例如钻取、framework manager 中度量指标的使用以及从 Cognos 报告中动态调用数据挖掘。
cognos下载地址提供给感兴趣的朋友,可以去试试,效果非常惊艳哟!!!
http://bigdata.evget.com/product/200.html
更多大数据与分析相关行业资讯、解决方案、案例、教程等请点击查看>>>
详情请咨询在线客服!
客服热线:023-66090381


