IBM SPSS 软件家族预测分析模型的商业应用初探系列
Statistics 和 Modeler 作为 IBM SPSS 软件家族中重要的成员,是专业的科学统计、数据挖掘分析工具,其具有功能强大,应用广泛的特点。其核心 组成部分——预测分析模型,不仅是软件功能实现的关键,同时也是软件应用的关键。
Statistics 中的模型侧重于统计分析技术, 而 Modeler 则侧重于数据挖掘技术。它们都依据现有数据,运用某个或某几个特定的算法,来预测用户所关注信息的未来值。Statistics 和 Modeler 提供众多的预测模型,这使得它们可以应用在多种商业领域中:如超市商品如何摆放可以提高销量;分析商场营销的打折方案,以制定新的更为有效的方案;保险公司分析以往的理赔案例,以推出新的保险品种等等,具有很强的商业价值。
Statistics 和 Modeler 产品中含有大量基于高级数学统计算法的预测模型,为了保证算法的严密性及结果的精确性,模型往往还需要许多详细的参数设定,这样就要求用户具有一定的统计专业知识,只有理解预测模型中的各项设置及运算结果的真实意义,才有可能结合结果做出正确的决策判断;另外,为了满足不同行业用户的需求,Statistics 和 Modeler 涉及到数学领域中多个不同的范畴,即使专业用户也很难了解所有模型,从而挑选出最适合他们应用的模型。
因此,为了让更多的用户更好更准确地使用我们的产品,最大地发挥其商业价值,我们将通过一系列的相关文章来介绍 IBM SPSS 软件家族中 Statistics 和 Modeler 的典型预测模型以及他们在解决相应的商业问题中的实际应用。
本系列文章从实际问题出发,通过一些实际生活中常见的商业问题来引出 IBM SPSS 软件家族中的典型预测模型,手把手地指导用户如何在软件中对该模型进行设置,如何查看运行结果,讲解运行结果的真实意义,最后引申到如何将该结果应用于解决这个具体的商业问题中来。用这种最直观简单的方式使即使缺乏统计学背景的用户也能容易地理解这些预测模型,从而很好地使用我们的产品。 同时,文中也涉及了一定的统计知识,使具有专业知识的用户能依此线索尽可能多的了解我们的产品的方方面面,从而选择最适合他们问题的模型。
下面,我们将会陆续给大家介绍 IBM SPSS 软件家族中的 Statistics 和 Modeler 包含的典型预测模型。
商业保险理赔案例
商业保险公司经常需要受理客户的理赔要求,这些以往的理赔案例记录就构成了经验数据。保险公司希望根据经验数据分析影响理赔金额的因素,以及影响程度的定量关系, 并使其服务中心能够在处理客户理赔案例的电话交流中,在得到相关保单信息和索赔要求之后立刻预估出理赔金额,缩短理赔处理时间,从而提高其服务质量。并且通过进一步分析,为公司降低运营风险提供决策支持。
这里我们主要研究和固定资产相关的理赔案例。理赔案例数据的主要变量信息如表 1 所示。其中,测量尺度为标度测量的变量是连续型变量,测量尺度为名义测量或有序测量的变量是离散型变量。
表 1. 固定资产理赔案例数据的主要变量信息
| 字段名 | 含义 | 类型 | 测量尺度 |
|---|---|---|---|
| claimid | 理赔案例 ID | 字符串 | Nominal(名义测量) |
| incident_date | 事故发生日期 | 日期 | Scale (标度测量) |
| claim_type | 理赔类型 | 数值 | Nominal |
| uninhabitable | 固定资产是否不易居住 | 数值 | Nominal |
| claim_amount | 理赔金额 ( 千元 ) | 数值 | Scale |
| fraudulent | 是否为欺诈索赔 | 数值 | Nominal |
| policyid | 保险单 ID | 字符串 | Nominal |
| policy_date | 投保日期 | 日期 | Scale |
| coverage | 保险责任范围金额 ( 千元 ) | 数值 | Scale |
| deductible | 可扣除金额 | 数值 | Scale |
| townsize | 居住城镇大小 | 数值 | Ordinal(有序测量) |
| gender | 性别 | 数值 | Nominal |
| dob | 出生日期 | 日期 | Scale |
| edcat | 受教育程度 | 数值 | Ordinal |
| job_start_date | 开始工作时间 | 日期 | Scale |
| retire | 是否已退休 | 数值 | Nominal |
| income | 家庭收入 ( 千元 ) | 数值 | Scale |
| marital | 婚姻状况 | 数值 | Nominal |
| reside | 家庭成员人数 | 数值 | Scale |
| occupancy_date | 开始居住日期 | 日期 | Scale |
| primary_residence | 固定资产是否作为主要住所 | 数值 | Nominal |
线性回归模型是一个应用广泛的模型分析方法,对解决这类问题非常合适。IBM SPSS Statistics 软件是一个被广泛使用的统计分析和预测软件,它提供了十分强大的线性回归分析功能。本文将介绍线性回归模型的基本概念,以及如何使用 Statistics 当中最新的“自动线性建模”功能来解决这个商业案例。
线性回归模型简介
线性回归模型基本概念
如果我们用变量来描述客观存在的事物,那么掌握变量(事物)间的内在规律并借以指导我们的行为是十分重要的。有些变量间的关系可以称为确定性的关系,比如销售额 y 与销售量 x 之间的关系可以表示为 y=p*x(p 是商品单价)。但有些变量间的关系就不能用这种确定性的函数来表达,比如:工资收入与教育程度的关系,健康程度与年龄的关系,等等。对于这类 非确定性关系,我们需要从以往的大量数据当中,通过统计分析方法来确定他们之间的关系,并用适当的数学形式进行描述。
回归分析就是一种用来确定两个或两个以上变量间基于统计的定量关系的分析方法。用这种方法得到的变量间关系的数学描述就是回归模型。如果模型所描述的变量关系是线性 的,则被称为线性关系。其中,一元线性回归描述的是一个变量(主要因素)对另一个变量的影响。而现实生活中应用更多的多元线性回归,即多个变量对某一个变量的影响。我们可以 用下面的公式来表达多元线性回归模型:
公式 (1) 当中,Y 被称为因变量 ( 或目标变量 ),Xj(j=1~n) 被称为自变量 ( 或预测变量 )。b0 被称为截距 ( 或常数项 ),bj(j=1~n) 是自变量的系数,被称为回归系数 ,表示当其他自变量不变,Xj 每改变一个单位时,因变量的平均变化量。注意公式 (1) 是相对于整个样本数据的,如果从个体角度 ( 比如单个理赔案例 ) 来看,线性回归模型可以被改写 为公式 (2) 的形式,其中 ei 是随机误差,被假定为服从均数为 0 的正态分布,即对每一个个体而言,当知道所有自变量取值时,我们能确定的只是因变量的平均取值,个体的因变量具 体取值是在平均值附近的一个范围内,而具体值与平均值之间的差异 ( 即 ei) 被称为残差,是回归模型对各种随机的、不确定的影响因素的统一描述。
建立线性回归模型的主要目标就是通过统计方法对回归系数进行参数估计,确定上述线性表达式。在此基础上,我们可以进行各种分析,获取有价值的信息。
线性回归分析的基本步骤
通常来说,和其他统计分析与数据挖掘方法类似, 线性回归分析包括建立模型、模型评价和利用模型进行预测等几个步骤。在正式建模前,有时需要对数据进行预处理,我们将在后面进行介绍。
我们可以从样本数据出发,利用回归分析确定变量间的线性表达式,即用统计方法估计出线性表达式当中每个回归系数的取值,这就是建立模型的过程。之后,我们可以对这个线性表达式进行可信程度的统计检验,并评价模型的质量,也可以对模型做进一步的分析,寻找出在影响因变量的多个自变量中,哪些自变量对因变量的影响更为显著,哪些自变量对模 型的贡献更加重要,这些都是模型评价的过程。然后,我们可以将这个关系表达式运用到新的数据集上,在知道所有自变量取值的情况下,根据关系表达式计算出因变量的取值,并利用统计方法评价预测值的精确程度,这就是利用已经建立好的模型进行预测的过程。
IBM SPSS Statistics 的线性回归分析模块简介
作为 IBM 分析与预测解决方案的重要组成部分,IBM SPSS Statistics 是一款面向商业用户、数据分析专家、科学统计程序设计人员等具有不同知识背景的用户的、 综合性的、易于使用的科学统计和预测分析工具。其操作简便,分析准确、结果显示直观明了,一直以来就被广泛使用。
在 Statistics 中的 Regression(回归分析)菜单中包含的功能模块很多,包括线性回归分析和非线性回归分析。其中能够做“简单线性回归”和“多元线性回归”分析的模块有 Linear( 线性回归 ) 模块和 ALM 模块。Linear 模块早已被广泛应用,其功能强大,操作相对比较复杂,更适合具备专业知识的用户使用。ALM 模块,全名叫做 Automatic Linear Modeling(自动线性建模),可以帮助我们用简单的操作完成多元线性回归分析,并且能够处理自变量当中存在离散型变量的数据,是从 Statistics 19 开始新增加的功能,既能够满足专业用户的需要,也能够方便普通用户进行线性回归分析。下面,我们重点讲解用 Statistics 进行数据预处理和使用 ALM 进行分析的步骤。
用 Statistics 进行数据预处理
数据的质量好坏对建模的质量会产生很大的影响。质量不好的数据会导致模型无法反映真实的关系。因此,我们需要先对原始数据进行预处理,消除那些影响建模的因素。预处理 操作包括:调整日期和时间数据,处理离群值和缺失值,合并离散型变量的类别,调整测量尺度等等。
图 1. 数据预处理示例
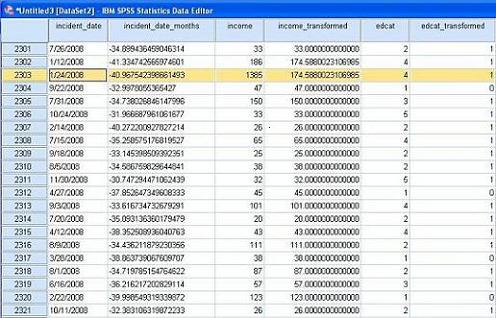
我们可以在 Statistics 中手动进行数据预处理,图 1 显示了本商业实例中的部分数据在预处理前后的取值情况。第一列 incident date(事故发生日期)的原始数据格式是“月 - 日 - 年”,我们必须将它们转换成一个数值才能进行数值计算和建模,预处理方法是将日期数据转换为距离某参考日期的月份数目。在本例中我们选择当前日期为参考日期,于是日期被转换为第二列显示的负实数。第三列 income(家庭收入)当中存在一些离群值,比如第 2303 行当中的收入 1385(千元),远远高于平均水平。为了使模型不被这些数量不多但很影响平均值的数据所破坏,偏离真实的拟合曲线(或直线),需要用特定的算法将其取值改变为一个合理的数值。因此,在第四列中该离群值被一个相对接近平均值的数值所取代。对于第五列“教育水平”, 原始数据当中类别比较多,有“高中未毕业”、“高中水平”、“大学水平”等五种类别,分别用 1-5 代表。预处理过程会对数据进行分析,必要时对类别进行归并,以使其与目标变量的关联最大化,在本例当中,发现高中以上水平四个类别的理赔案例其特征比较相似,因而归并的结果是只有两个类别,即“高中未毕业”与“高中以上水平”,用 0 和 1 表示,如第六列所示。
Statistics 软件当中有一个自动预处理模块,即 ADP,其全称为 Automatically prepare data(自动数据准备),用户在使用 ALM 进行建模之前,可以选择预先执行 ADP,以提高数据的质量。这个过程在后台被执行,使用者不用太关心。经过预处理的数据,其变量名会在后面增加一个“_transformed”后缀。
使用 ALM 进行线性回归分析
使用 Forward Stepwise 方法建立线性回归模型
首先我们要通过 Statistics 的菜单“File”->“Open”->“Data …”打开理赔案例数据文件。在数据集界面中,左下角显示了两个视图的 Tab 页:Data View(数据视图)和 Variable View(变量视图)。数据视图用来显示数据文件当中实际的数据。变量视图则显示了数据文件当中各个变量的相关信息,比如变量名称、存储类型、标签和测量尺度等等,其作用相当于数据库当中的元数据。
然后,我们通过菜单“Analyze”->“Regression”->“Automatic Linear Modeling …”来打开 ALM 模块的操作对话框, 如图 2 所示:
图 2. ALM 对话框 - 设置变量
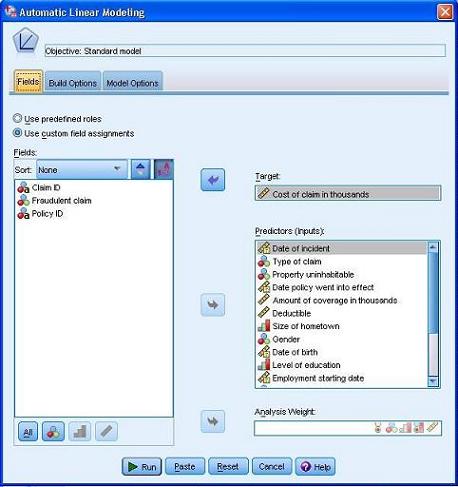
既然是要分析和预测理赔金额,我们当然选择 Cost of claim in thousands(理赔金额 ( 千元 ))作为因变量。在 Fields( 字段 )Tab 页当中,把该变量选入到 Target(目标)文本框当中。像理赔案例 ID、是否为欺诈索赔和保险单 ID 这几个变量,和本次分析目的关系不大,被留在左边的文本框当中,先不予考虑。剩下的变量就统统作为自变量,选入到 Predictors(inputs)(预测变量 ( 输入 ))文本框当中。
我们打开名为 Build Option(构建选项)的 Tab 页,如图 3 所示:
图 3. ALM 对话框 - 设置自动数据准备
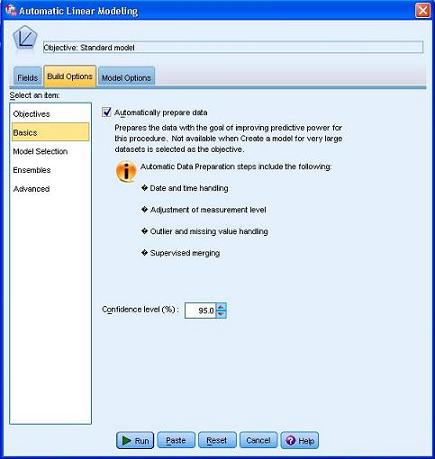
选择 Basics(基本选项)子页面, 可以看到默认选择了 Automatically prepare data 选项,这个选择会在运行 ALM 之前首先运行 ADP,对数据进行预处理。
打开 Model Selection( 信息选择 ) 子页面,如图 4 所示 :
图 4. ALM 对话框 - 设置信息选择方法
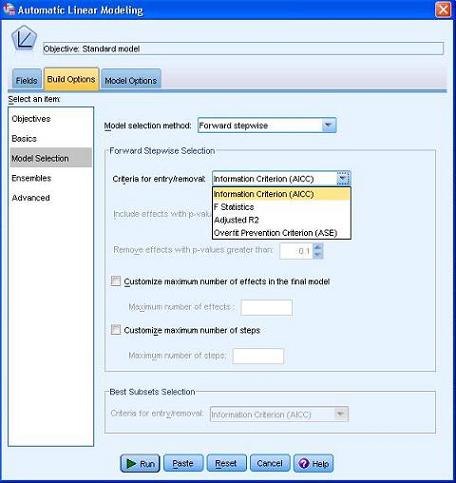
在 Model Selection method(信息选择方法)中默认选择了 Forward Stepwise(前向逐步)方法。在 Forward Stepwise Selection(前向逐步选择)区域当中的 Criteria for entry/removal(输入 / 删除标准)下拉框中,有“Information Criterion AICC(信息准则 (校正的 Akaike))”、“F Statistics(F 统计)”、“Adjusted R2(调整后的 R2)”和“Overfit Prevention Criterion(过度拟 合防止标准(ASE))”几种判断标准。默认选择“信息准则 AICC”。我们不改变这些默认设置。点击 Run(运行)按钮,可以看到一个新的窗口被打开,这就是用于显示建模结果的 Output(输出)视图。如图 5 所示:
图 5. Output 输出视图
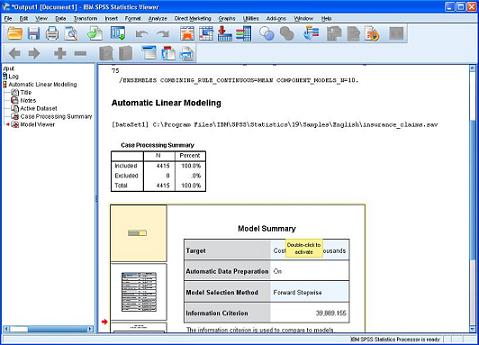
在标题 Automatic Linear Modeling 下面,我们可以看到建模所使用的数据文件的系统路径名。紧接着,Case Processing Summary(案例处理汇总)表格显示了总共有 4415 条数据被包含,而被排除的无效数据为 0 条。 在表格的下面,是 Model Viewer(模型浏览器)。它提示用户可以通过双击激活它。我们双击它,打开模型浏览器,如图 6 所示:
图 6. 模型概要视图
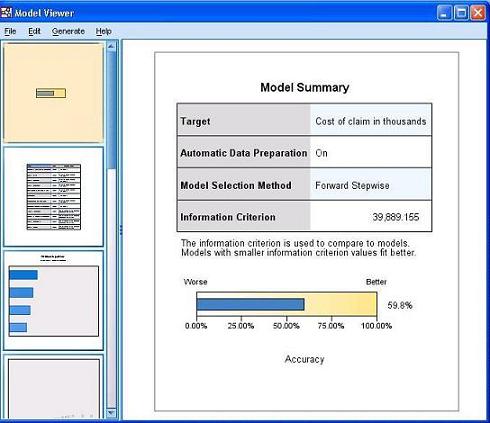
模型浏览器首先给我们展示的是图 6 当中的 Model Summary(模型概要)视图。从中我们可以看出:目标变量(即因变量)的名称是“理赔金额”,而且“自动数据准备”功能被设置为“开”。而 Model Selection Method(信息选择方法)采用了 Forward Stepwise。而 Information criterion(信息准则)的取值是 39.889,我们可以用这个值对本模型和用其他方法建立的模型进行比较。
我们从模型显示器左边较小的示意图中,打开第二张图:“自动数据准备”,如图 7 所示:
图 7. 自动数据准备视图
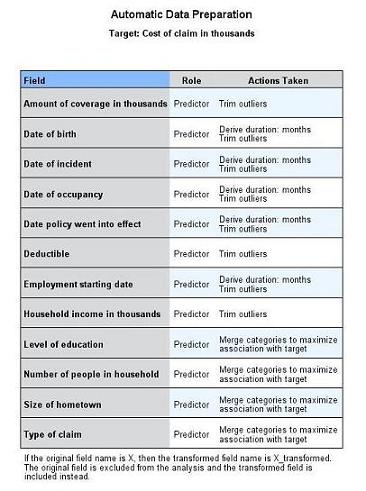
可以从 Action Taken 一列的说明文字中看到:Date of incident(事故日期),Date of Occupancy(居住日期)等变量的数据已被转换成距离参考日期的月份数。变量 Household income in thousands(家庭收入 ( 千元 ))的离群值也已被替换。而变量 Level of education(教育水平)的类别也被合并,使其和目标变量的关联最大化。 让我们打开 Model Building Sumary(模型构建汇总)视图。如图 8 所示:
图 8. 模型构建汇总视图
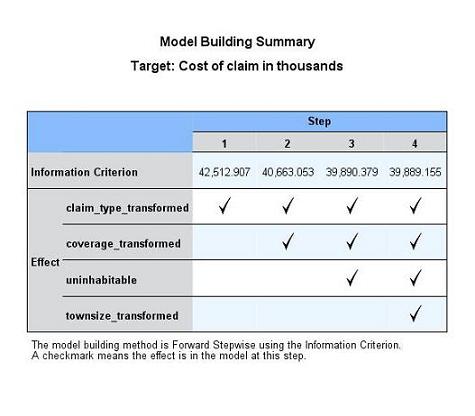
可以看到,共有 4 个自变量被选入到最终的模型,如图第 4 列所示,它们是“理赔类型”、“保险责任范围金额”、“固定资产是否不易居住”和“居住城镇大小”。这些变量在模型当中被称之为 Effect(效应)。Forward Stepwise 是通过迭代的过程建模的。从视图中可以看出,迭代过程总共有 4 步,变量“理赔类型”在第一轮迭代中就被选入模型,变量“保险责任范围金额”在第二轮迭代中被选入模型,以此类推。我们选择的用于判断模型好坏的标准是 AICC,该标准是取值越小越好。可以看到,第四步迭代终止时取得的 AICC 值最小。
那么,在被模型选入的自变量当中,到底哪些变量在模型当中更为重要,或者说哪些变量对因变量的影响更大呢?让我们来看看 Predictor Improtance(预测变量重要性)视图。如图 9 所示:
图 9. 预测变量重要性视图
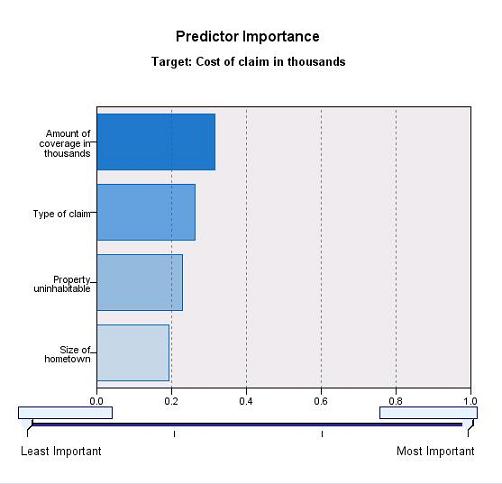
该视图按照变量的重要性进行了排序,重要性判断准则取值越大,柱状图越长,变量也越重要。可以很容易地看出,“保险责任范围金额”是最重要的变量,“理赔类型”次之,而“居住城镇大小”的影响力是最小的。
我们已经知道,多元线性回归模型主要是由线性表达式的回归系数确定的。下面,我们就来看看模型最重要的信息——回归系数的取值。打开 Coefficients(系数)视图,如图 10 所示:
图 10. 系数视图的图表格式
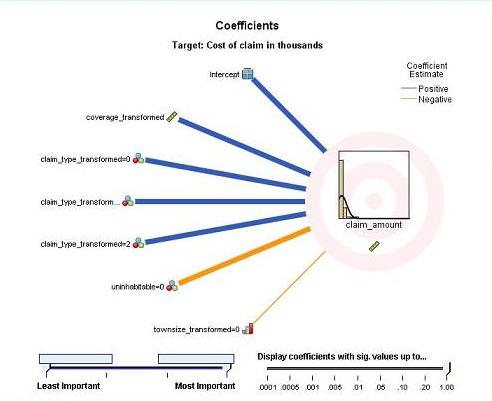
从图中的连线数目可以看出,系数个数明显比变量个数多,对于包含有常数项和离散变量的模型,其模型项(或参数项)个数往往多于变量个数。离散变量的取值不是连续的,而是分散、有限的几种类别,比如 Claim Type(理赔类型)就有 4 种类别。模型将离散变量的每一种类别作为一个模型项,而将一个连续变量作为一个模型项,每个模型项都有一个系数。因此,连续型变量 Coverage(保险责任范围金额)对应一条连线 , 理赔类型的三种类别对应三条连线(有一种类别的系数值为 0,没有显示)。从模型项对应连线的粗细可以大致看出其显著性水平,显著性水平越高其连线越粗,在模型当中越重要,这从另一个角度反映了该模型项对应的变量的重要程度。蓝色的连线表明该系数为正值,说明该模型项与目标变量是正的线性关系的,产生积极影响,其取值增大时目标变量取值也增大。而黄色的连线表明该系数为负值,与目标变量是负的线性关系,产生消极影响。
我们通过视图下方的下拉框,将该视图的显示格式从图表格式改变为表格式,如图 11 所示:
图 11. 系数视图的表格式
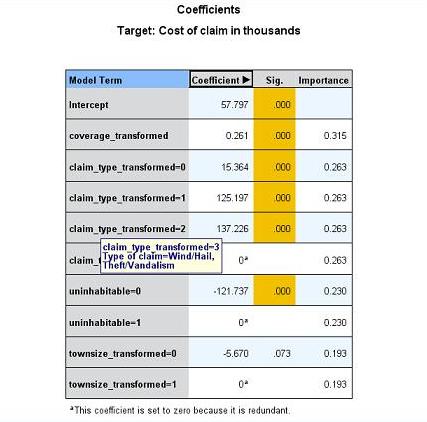
我们可以从系数的取值中分析出这些模型项与因变量之间的定量关系。比如“保险责任范围金额(千元)”的系数值为 0.261,它表明当其他模型项的值不发生变化时,“保险责任范围金额”每增加 100(千元),因变量增加 100*0.261=26.1(千元)。类似的,理赔类型 2(污染物损害理赔)的系数值是 137.226,而理赔类型 3(风灾损害理赔)的系数值为 0(一般来说,对于一个离散变量的所有类别对应的模型项,总有一个模型项的系数取值为 0,作为比较其他类别的基准),它说明一次污染物损害理赔要比风灾损害理赔要高出 137.226(千元),是所有理赔类型当中理赔金额最高的。当然,所有这种定量关系都是基于统计方法算出的估计值。
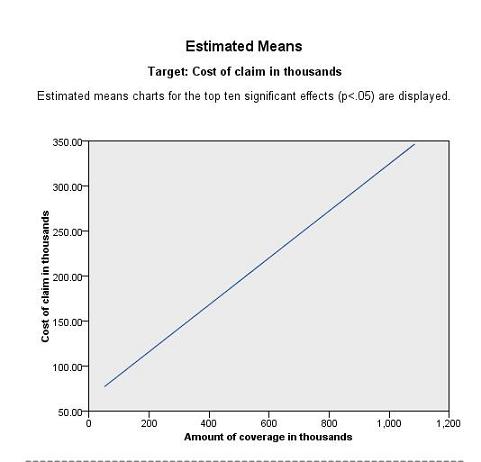
还有一种参考价值比较高的视图,是 Estimated Means(估计的平均值)视图,如图 12、图 13 所示。它为我们显示了前十个显著效应 (p<0.05) 的估计均值图表。这为我们提供了另一种视角,用直观的图形方式帮助我们分析变量间的关系。比如,图 12 反映的就是“保险责任范围金额”和“理赔金额”之间的关系。可以看出它们之间有着明显的线性关系。也就是说,对于保险责任范围金额较大的保单, 其理赔额度也更高。
图 12. 均值估计视图 - 保险责任范围金额与理赔金额
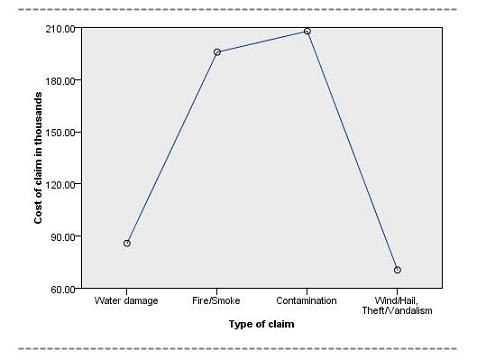
我们再来看看反映“理赔类型”与“理赔金额”之间关系的均值估计视图,如图 13。可以看出,相对于其他两种理赔类型,“污染灾害理赔”和“火 / 烟灾害理赔”与高额理赔的关联更加密切,一般会要求高额赔付。
图 13. 均值估计视图 - 理赔类型与理赔金额
以上就是模型浏览器当中一些主要的分析结果,它们用直观的图表描述了线性回归模型,提供了详细准确的分析结果,可以为我们的决策提供有力的支持。
使用 Best Subsets 方法建立线性回归模型
ALM 拥有不同的建模方法,我们可以通过比较不同方法建立的模型,使我们对问题的分析更加全面和准确。下面我采用 Best Subsets 方法来建模。
如图 14 所示 , 重新打开 ALM 的对话框,选择 Build Option 页 , 在 Model Selection method(信息选择方法)中选择 Best Subsets(最佳子集)方法。在 Best Subsets Selection(最佳子集选择)区域当 中的 Criteria for entry/removal(输入 / 删除标准)下拉框中,有“信息准则 AICC”、“调整后的 R2” 和“过度拟合防止标准(ASE)”几种判断标准。我们选择信息准则 AICC 建模。
图 14. 设置信息选择方法 -Best Subsets
模型建好后,打开模型显示器当中的 Model Summary(模型概要)视图,如图 15 所示。
图 15. 模型概要视图 -Best Subsets
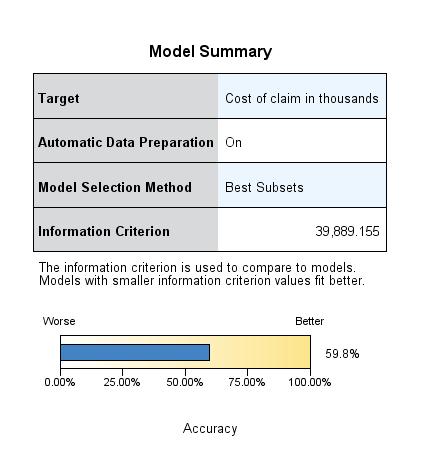
可以看到,对于 Best Subsets 方法建立的模型,Information criterion(信息准则),即 AICC 的值是 39.889, 和 Forward Stepwise 方法建立的模型 的 AICC 值相同。
打开模型构建汇总视图视图,如图 16 所示。
图 16. 模型构建汇总视图 -Best Subsets
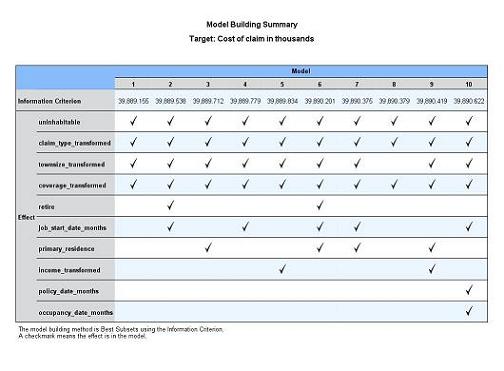
Best Subsets 方法不仅仅只建立一个模型,而是采用穷尽搜索的方法,在所有可能的模型当中选择 10 个(默认设置)最优的模型,每个模型所包含的自变量有可能不相同。其中最好的模型被显示在最左边,其 AICC 值最小。该模型当中的自 变量和使用 Forward Stepwise 方法建立的模型当中的自变量完全相同。该模型的 AICC 值就是模型概要视图当中显示的信息准则值。两种方法最终确定的模型的 AICC 值相同,被选入的自变量也相同,这说明 Forward Stepwise 方法对本案例数据比较适用,能够找到最好的模型。
一般来说,Forward Stepwise 方法采用迭代方法,不能保证每次都搜索到最优的模型,通常会找到接近最优的模型。而 Best Subsets 方法,总是能够选出最优的模型,但运行时间相对较长。因此,对于自变量非常多的数据,一般选 择 Forward Stepwise 方法。而对于自变量不多的数据,Best Subsets 方法则是更好的选择。
预测和输出模型
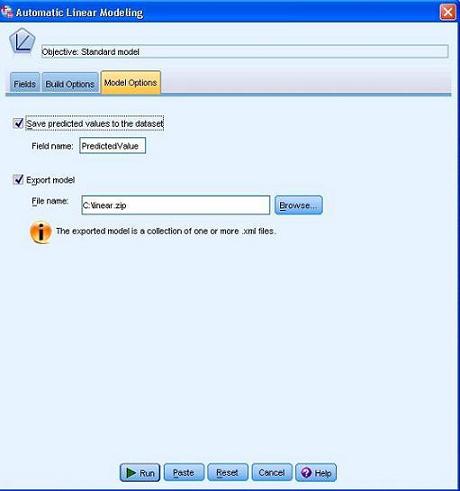
如果要在原始数据上计算理赔金额的预测值,并和其原值进行比较,看模型拟合的好坏,可以打开 ALM 对话框,选择 Model Option( 模型选项 ) 页面,如图 17 所示。选择“Save predicted values to dataset(将预测值保存到数据集中)”。
图 17. ALM 对话框 - 设置计算预测值和输出 PMML
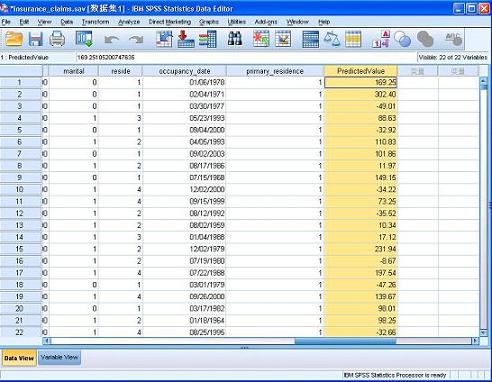
这样,数据集视图当中会增加一列,显示计算出的理赔金额的预测值。如图 18 所示。
图 18. 计算出的预测值
为了方便对新数据进行预测,我们可以如图 17 所示,选择 Export model(导出模型)选项,并指定包含 PMML 文件的 zip 包的文件名和路径,就可以在建模后输出模型到 PMML 文件当中。 我们可以用 Statistic 对新数据进行预测,也可以使用 IBM SPSS Modeler 或其它厂商的软件,利用输出的 PMML 对新数据进行预测。
总结
运用 ALM 可以对商业保险公司的固定资产理赔案例进行详尽的分析。保险公司的服务中心采用该模型在电话交流时进行实时预测,能够减少理赔处理时间,提高了服务水平。ALM 建立的线性回归模型还可以提供很多信息,比如哪些变量重要性高,对理赔金额影响更大,是积极的还是消极的影响,哪些理赔类型的理赔金额较高等等。有了这些分析结果,保险公司可以有针对性的采取措施降低运营风险,提高效益。
ALM 可以被应用到商业、科研和教育领域等多个领域,有着十分广泛的应用。无论是专业用户,还是普通用户,ALM 都可以提供科学准确的分析和预测,是一个功能强大,使用方便的建模和分析工具。
SPSS产品下载地址如下,赶紧来试试吧!
spss modeler:http://bigdata.evget.com/product/168.html
spss statistics:http://bigdata.evget.com/product/330.html
更多大数据与分析相关行业资讯、解决方案、案例、教程等请点击查看>>>
详情请咨询在线客服!
客服热线:023-66090381


