SparkBench简介
SparkBench是Spark的基准性能测试项目,由来自IBM Watson研究中心的五位研究者(Min Li, Jian Tan, Yandong Wang, Li Zhang, Valentina Salapura)发起,并贡献至开源社区。
SparkBench的测试项目覆盖了Spark支持的四种最主流的应用类型,即机器学习、图计算、SQL查询和流数据计算。每种类型的应用又选择了最常用的几个算法或者应用进行比对测试,测试结果从系统资源消耗、时间消耗、数据流特点等各方面全面考察,总体而言是比较全面的测试。
所有的研究结果以论文的形式公开发布,原文可在SparkBench的官方网站下载,测试相关的数据和代码也可下载供测试使用,本文将主要的研究结果呈现给大家。
SparkBench的目的
SparkBench最主要的目的是通过基准性能测试,研究Spark与传统计算平台的不同之处,为搭建Spark平台提供参考和通用指导原则。具体而言SparkBench可以在如下场景中发挥作用:
1、重点领域需要有参考数据和定量分析结果,包括:Spark缓存设置、内存管理优化、调度策略;
2、需要不同硬件、不同平台中运行Spark的性能参照数据;
3、寻找Spark集群规划指导原则,帮助定位资源配置中的瓶颈,通过合理的配置使资源竞争最小化;
4、需要从多个角度深入分析Spark平台,包括:负载类型、关键配置参数、扩展性和容错性等
SparkBench测试项目
SparkBench主要的的测试项目,按负载类型划分如下表所示:
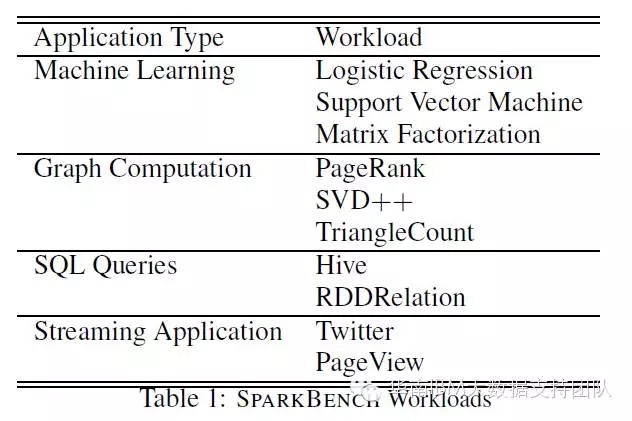
其中机器学习类型选择了最常用的逻辑回归、支持向量机和矩阵分解算法,这些是在进行数据归类或者构建推荐系统时最常用的机器学习算法,很有代表性。图计算类别中选取了最流行的三种图计算算法:PangeRank、SVD++和TriangleCount,各具特点。SQL查询类别同时测试了Hive on Spark和原生态的Spark SQL,测试覆盖最常用的三种SQL操作:select、aggregate和 join。流计算类别分别测试了Twitter数据接口Twitter4j的流数据和模拟用户访问网页的流数据(PageView)。
除了表中列出的测试项目,目前最新版本的SparkBench还包括很多其他负载类型的测试项目:KMeans,LinearRegression,DecisionTree,ShortestPaths, LabelPropagation, ConnectedComponent, StronglyConnectedComponent,PregelOperatio。
SparkBench的测试数据
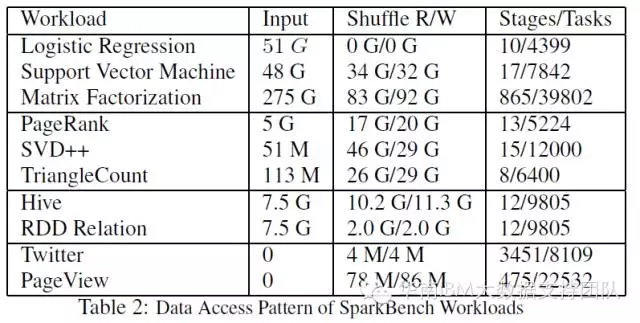
SparkBench大部分测试数据由项目自带的数据生成器生成,其中SQL查询使用模拟生成的电子商务系统的订单数据,流计算使用的分别是Twitter数据(Twitter4j每60秒发布一次最热门的标签数据)和模拟生成的用户活动数据(用户点击、页面访问统计等等)。具体测试项目的数据量如下表所示:
SparkBench的研究方法
SparkBench基准测试通过每个测试项目指标的纵向对比,和多个测试项目指标的横向对比,来发现不同工作负载的规律,目前版本研究的主要指标是:任务执行时间、数据处理速度和对资源的消耗情况。在未来的版本中会陆续加入其它方面的指标进行研究,包括shuffle数据量, 输入输出数据量等。
SparkBench测试环境
公开发布的结果是基于IBM SoftLayer云计算平台的测试环境:总共11台虚拟主机,每台配置4核CPU,8GB的内存和2块100GB的虚拟硬盘(一块盘分配给HDFS,另一块做为Spark本地缓存使用),网络带宽1Gbps。11台虚拟主机中,只有1台作为管理节点,剩下的10台作为HDFS数据节点和Spark计算节点,每个Spark计算节点只设置1个executor并分配了6GB的最大内存。
可能会有人担心虚拟机测试结果会与物理环境测试结果相差过大,对于这一点论文指出,经过实际测试,在该虚拟环境中的测试结果与同等配置硬件环境的测试结果相比,相差不超过5%。
背景交代完毕,下面是最重要的内容:SparkBench测试结果及分析!
SparkBenc测结果和分析
任务运行时间对比
MapReduce作业分为Map和Reduce两个阶段,类似的Spark作业也可分为两部分:ShuffleMapTask和ResultTask。前者由Spark DAG生成,会在不同节点间分发数据,产生一系列高代价的操作:IO、数据序列化、反序列化等。按这两个阶段(分别显示为Shuffle Time和Regular Time)统计的运行时间占比如下:
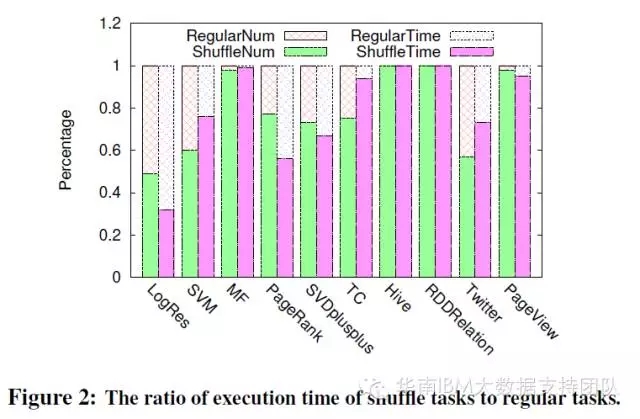
测试结果显示,除了逻辑回归测试项目中ShuffleMapTasks阶段运行时间占比小于一半,其他测试项目都超了过50%,其中HIVE SQL/Spark SQL和矩阵分解算法等这几个测试的ShuffleMapTasks时间占比接近100%! 论文中论述的原因是:SQL查询及矩阵分解算法都使用了大量的聚合和数据关联操作(RDD或表),比如矩阵分解算法中GroupBy操作就占用了约98%的时间,这样的操作会使Spark花费大量时间在不同Stage之间的协同和数据分发上。
测试项目的资源占比分析
我们摘选几个关键测试项目的测试结果呈现如下:
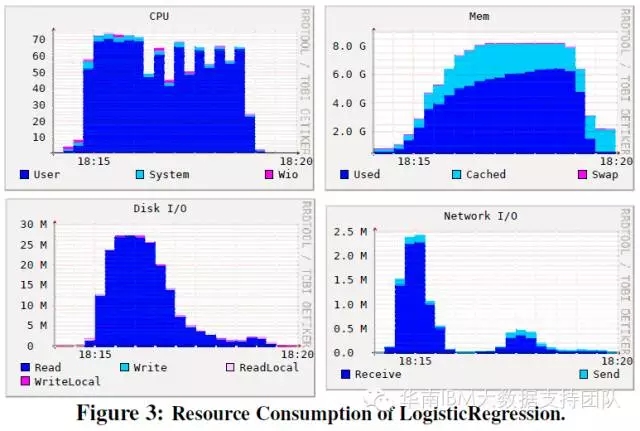
逻辑回归测试:对CPU和内存的占用较为平均,分别为63%和5.2GB;对磁盘IO的占用峰值出现在测试开始阶段,后继占用逐渐减少。
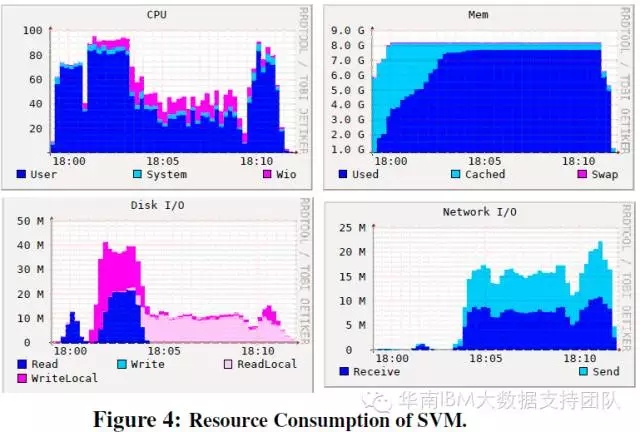
SVM测试项目:对CPU和IO的占用具有双峰的特点,分别在测试开始不久和测试结束前占用较多CPU和IO资源。
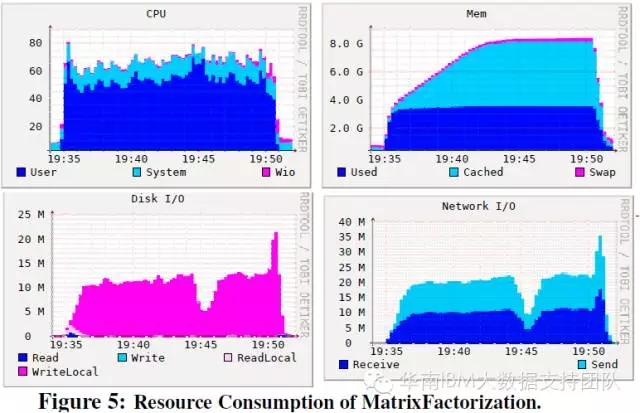
矩阵分解测试: 占用较高CPU和内存,对磁盘IO的占用特点是有大量的本地盘操作而不是HDFS操作,这是因为该工作负载产生大量的Shuffle数据,Shuffle是由本地盘的IO来完成的。
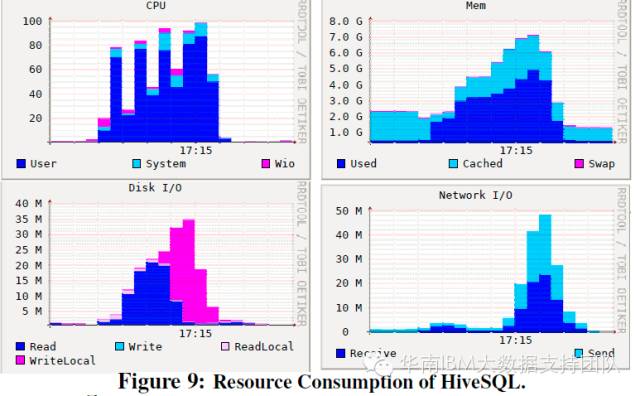
SQL查询测试项目:HIVE SQL和Spark Native SQL对资源的占用规律类似,都占用了将近100%的资源! 这与SQL计算中有大量的数据表关联有关。
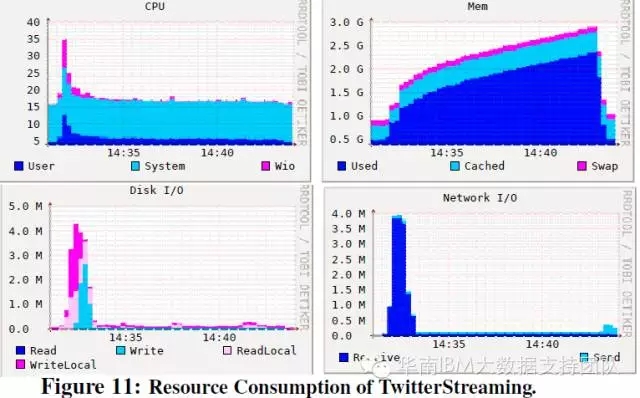
流计算测试项目:两个流计算测试项目的资源占用规律类似。与其他负载类型相比,除了内存占用逐渐变大,对其他资源(CPU/IO/网络)的占用率较低。
测试结果的指导意义
通过对四种工作负载、多个测试项目的结果分析,得到如下结论:
1. 内存资源对Spark尤为重要,因为所有类型的负载都需要在内存中保存大量RDD数据,因此系统配置时需要优先配置内存;
2. 进行优化时,Shuffle的优化异常重要,大部分负载超过50%的执行时间都用在Shuffle上。
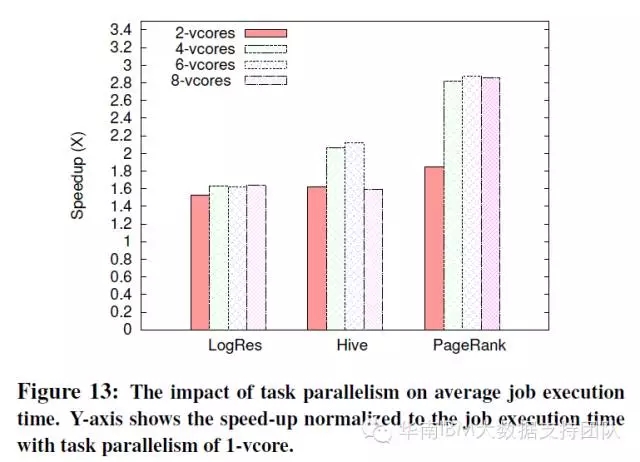
有趣!只增加CPU可能会降低性能
SparkBench测试还研究了增加CPU资源对负载性能的影响。测试中选用三种典型的负载(逻辑回归、PangeRank和Hive SQL),来研究线性增加CPU个数对任务执行时间的影响。
由于Spark中默认一个CPU Core分配一个Executor,只要系统CPU资源足够多,Spark会启动多个并行任务(Executor),因此增加CPU个数就是增加并发任务数量。而在现有环境中CPU核数从1增加到2,总体上都可以减少执行时间,成倍增加效率;但如果过度增加CPU可能不仅没能改善,反而会降低性能,参见HiveSQL测试结果:
更多大数据与分析相关行业资讯、解决方案、案例、教程等请点击查看>>>
详情请咨询在线客服!
客服热线:023-66090381


