数据处理工具的必要性
Hadoop的魅力在于提供了廉价的分布式数据存储和数据处理框架,让我们以极低的成本保存和处理海量数据。然而纯开源的Hadoop对使用者的技能仍然有较高要求:熟悉Java、Mapreduce接口才能编写数据处理程序;熟悉Hive sql或者Pig等才能使用各种工具语言编写数据处理逻辑。
对于大部分数据分析师和数据科学家来说,学习这些技能并不难,然而学习、使用这些底层的技能会消耗大量宝贵的时间,因此一款功能丰富、使用简单的数据处理工具无疑可以带来极大的帮助,可以为业务人员、数据分析师和数据科学家节省大量的时间和精力。BigSheets就是这样一款设计用来处理海量数据的图形化工具。
BigSheets功能介绍
BigSheets是对大数据进行数据处理、数据分析的电子表格工具,内置支持多种数据源,提供数据过滤、内容补全等多种实用的数据处理功能,可以合并和处理不同表格中的数据,也可以通过图表的形式对数据进行可视化展现,并提供了丰富的数据导入导出接口。
BigSheets架构介绍
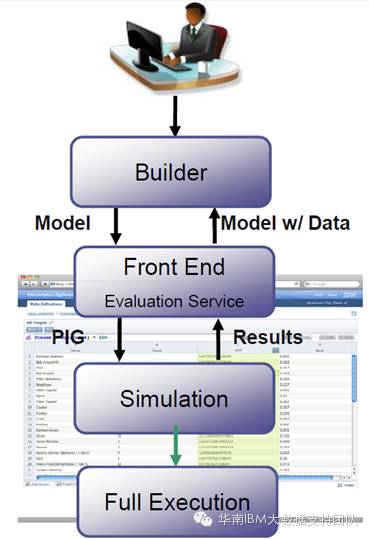
BigSheets在用户和Hadoop之间建立了一整套数据处理框架:用户在浏览器界面创建工作簿, 根据需要定义数据过滤、数据转换的处理流程;BigSheets引擎将前端输入的处理流程转换为可执行的作业(Pig);BigSheets在样本数据上运行数据处理流程,将结果展现给用户进行预览,等待确认;用户确认后,BigSheets将运算逻辑运行在全量数据上,并得到最终的处理结果。BigSheets的架构如下图所示:
BigSheets使用示例
本示例中展示了如何使用BigSheets对海量订单数据进行处理,演示了基本的数据处理,包括:数据解析、过滤、排序、合并和结果处理。需要处理的订单数据已提前上传至HDFS目录中。
步骤1, 登录BigSheets界面:
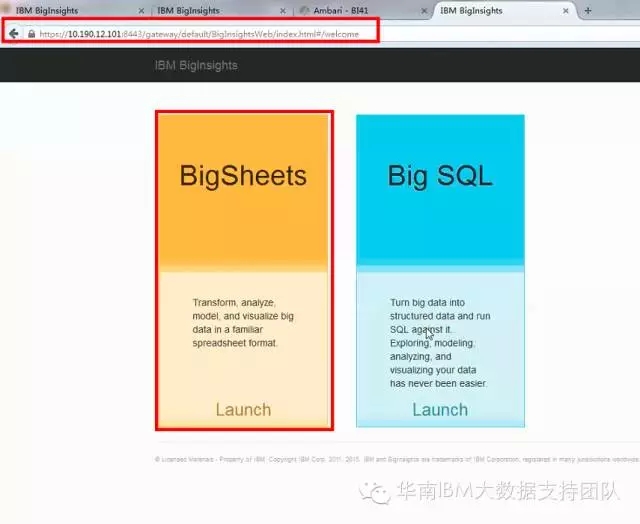
BigSheets提供基于浏览器的管理界面和用户交互界面,除了最基本的Hadoop组件HDFS/Yarn/Mapreduce外,BigSheets还依赖BigInsightsHome和Knox服务:BigInsightsHome服务提供了IBM增值组件(BigSheets/BigSQL/TextAnalytics)的统一访问界面;Knox为外部访问者提供了安全、统一的访问入口。
在浏览器地址栏输入地址: https://<管理节点
IP>:8443/gateway/default/BigInsightsWeb/index.html 访问,可使用默认用户guest/guest-password登陆:
步骤2, 将数据导入HDFS,并新建工作簿(Workbook):
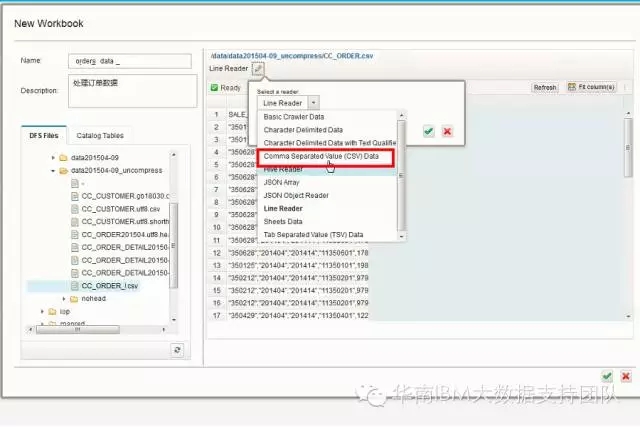
可以从本地文件/目录或者HDFS文件/目录创建BigSheets工作簿。BigSheets内置了多种数据解析器,包括:基本的网络爬虫数据,字符分割数据,CSV格式文本数据,Hive数据解析器,JSON数据解析器 和TSV数据等。下图展现了从HDFS中的CSV文件中创建Workbook数据源:
步骤3, 在生成的工作簿副本中定义数据处理逻辑:
从HDFS文件创建的初始工作簿是只读的,需要复制为新的工作簿后再增加数据处理逻辑。下图展示了对订单数据按照时间条件进行过滤,提取出需要处理的数据子集后,再根据时间条件进行排序。
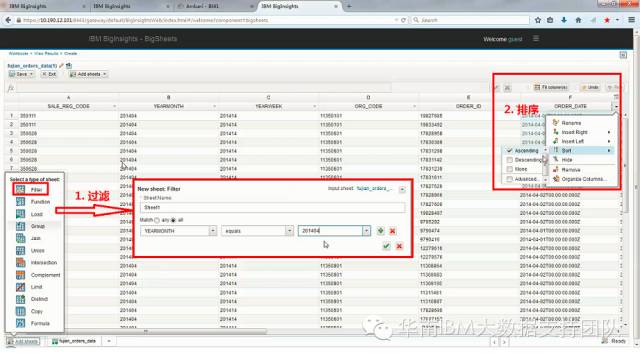
通常进行数据分析的数据源可能来自于多个数据源,需要根据实际情况对数据进行处理然后合并,下图中展示了将不同数据源的多余数据列删除,再通过Union操作将多个数据源的订单数据进行合并。
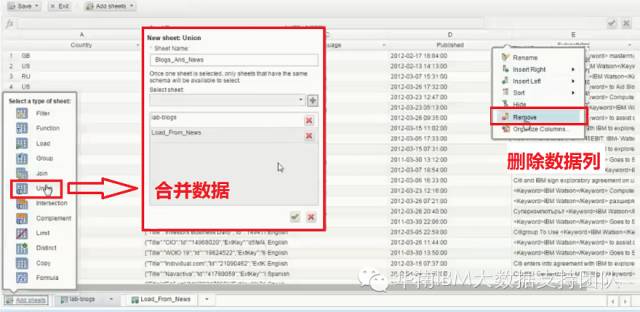
BigSheets提供了大量现成的处理工具,包括:
Filter:过滤不满足条件的数据,如用户名为空等;
Function: 添加数据处理函数(内置96种函数),如对输入值进行求和;
Load: 从其他工作簿中导入数据,如合并不同表格中的数据;
Jion: 关联多个表格中的数据,类似于SQL语句中的Join;
Group: 数据分组:对数据进行分组并对每组数据进行相应的运算;
Union: 数据合并,将多个表格中的数据合并为一个;
Intersection: 数据交集,按指定列获取两个或多个表格中的重合数据,要求数据模式相同;
Complement: 数据取余,按指定列对数据进行取余,要求数据模式相同;
Limit: 限制数据中处理行数,按照Top(N)等顺序对处理的数据量进行处理;
Distinct: 除去表格中的重复值,每组重复的至只保留一个;
Copy: 从其他电子表中复制数据;
Formula: 添加数据处理公式。
定义好数据处理流程之后,可以从管理界面通过数据流图的方式,查看数据处理过程,如下图所示:
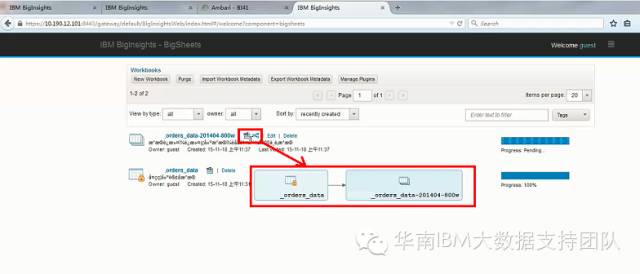
步骤4, 对全量数据进行数据处理,并保存结果:
在编辑数据处理过程中,在BigSheets中看到的显示结果,都是对数据集里的前2000行数据进行模拟处理后,显示最前面的50行数据。确认数据处理逻辑正确之后,点击“Run”按钮运行全量数据的处理。
BigSheets会在后台通过Pig启动MapReduce作业,并在前台通过进度条显示进度。待任务完成之后,便可以使用数据处理结果了。
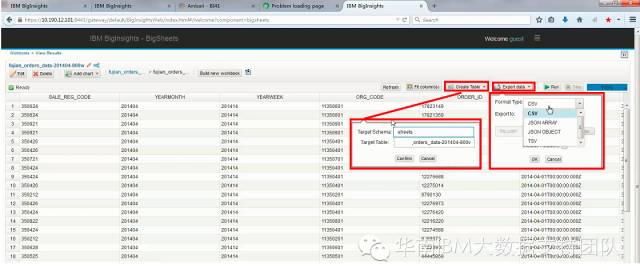
常见的三种使用场景如下:在BigSheets中使用数据,包括通过电子表格查看和画图等;为数据集创建BigSQL/HIVE数据表,再通过SQL/HIVE SQL访问数据;将电子表格的数据导出到HDFS,供外部使用。下图展现了如何在BigSheets中导出文件和创建数据表:
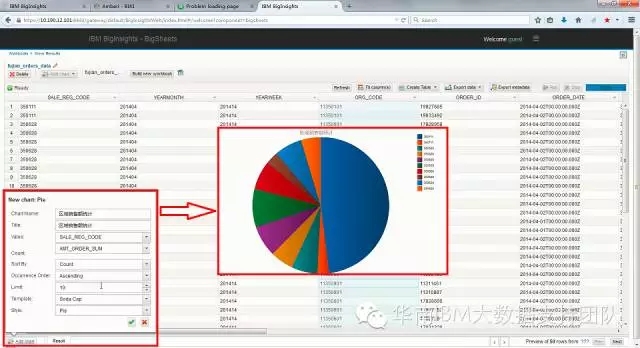
还可以根据需要直接画图,通过可视化图表的方式来展现数据。BigSheets支持各种常见的图表,包括饼图、柱状图、折线图、地理图等,下图展现了按照区域显示销售额的饼图:
后记
大数据分析中处理的数据量少则TB大到PB,数据处理是花费数据分析团队最多时间和精力的工作。BigSheets的数据处理能力,可以有效减少数据处理过程的开发和维护时间,是大数据分析团队不可多得的数据处理工具之一。
更多大数据与分析相关行业资讯、解决方案、案例、教程等请点击查看>>>
详情请咨询在线客服!
客服热线:023-66090381


