在上期发布的文章《分分钟让你学会使用DataStage连通企业级数据库》中,给大家详细介绍过DataStage广泛支持各种异构平台的数据库,提供多种功能强大、类型丰富的数据库连接器,满足企业数据集成所需:
- 提供企业级数据库连接器,例如DB2 Connector, Oracle Connector,Teradata Connector等;自带原生API接口,支持各种优化选项,实现高性能数据抽取和加载。
- 提供JDBC连接器(JDBC Connector),功能更加灵活,不仅支持传统数据库,而且还支持NoSQL数据库,例如Cloudant,MongoDB,Hive,Cassandra等。
- 提供ODBC连接器(ODBC Connector),支持所有提供ODBC驱动的数据库。
DataStage不仅可以全面支持结构化数据,同样也支持对非结构化数据的访问,例如TXT、CSV、XML、COBOL和Excel文件。今天与大家分享的最佳实践,就是如何通过DataStage的Unstructured Data组件来访问和读取Excel文件。
场景一:指定Sheet名和数据范围进行数据抽取
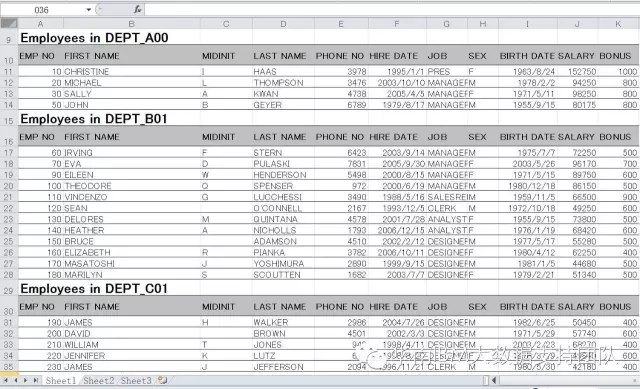
1. Excel文件名为Employee1.xls,包括3个sheet(sheet1, sheet2, sheet3),其中sheet1存放的是员工及部门信息,sheet2和sheet3都为空,数据样本如下:
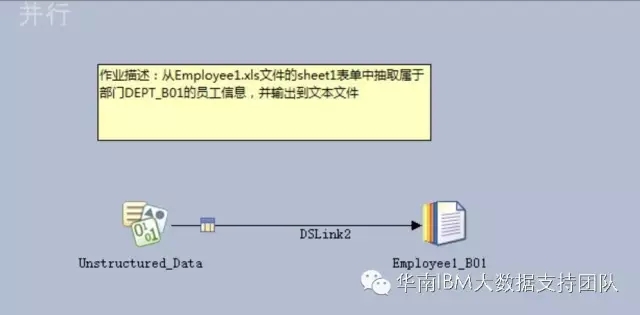
2. 设计DataStage作业,从Employee1.xls文件的sheet1表单中抽取属于部门DEPT_B01的员工信息,并输出到文本文件。
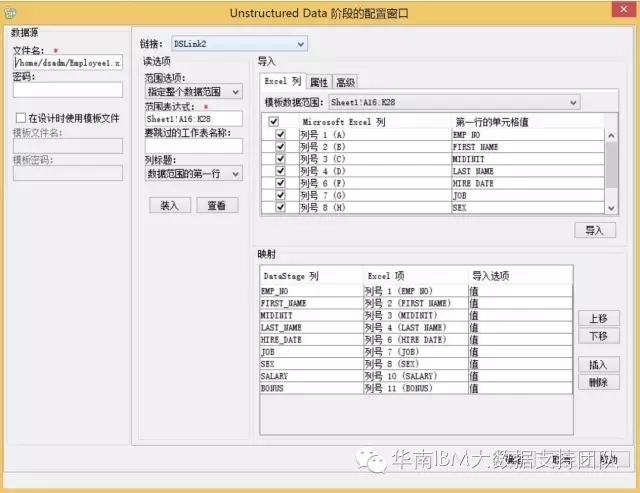
- 文件名:Excel源文件的文件名及目录路径;
- 范围选项:指定整个数据范围,表示从下面的范围表达式中读取数据;
- 范围表达式:指定读取数据的具体范围,即sheet1表单的A16:K28;
- 列标题:数据范围的第一行,表示第一行为字段名,所以从第二行开始抽取数据;
- Excel 列:对字段进行过滤,输出结果不保留源Excel sheet1表单的“PHONE NO”和“BIRTH DATE” 两个字段;
3. 编译并运行作业,结果数据如下:
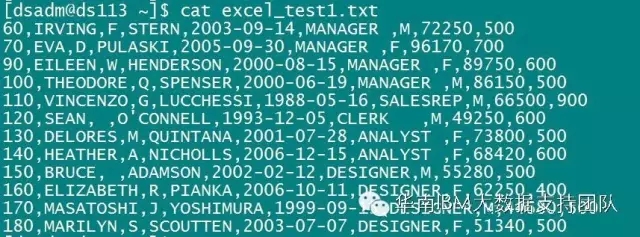
场景二:对Excel文件中的所有sheet统一进行数据抽取
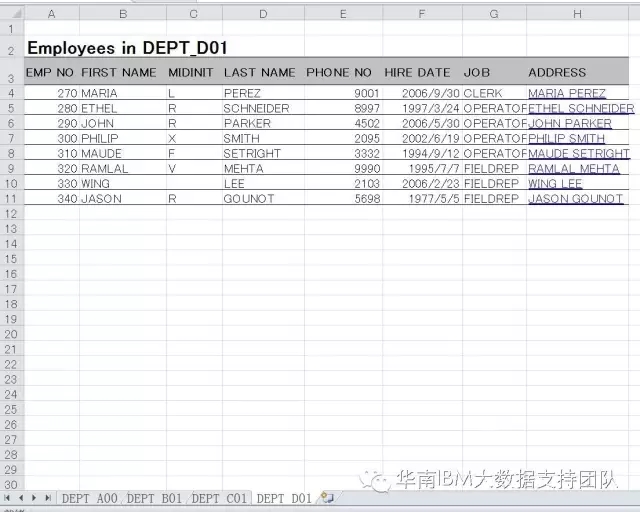
1、Excel文件名为Employee2.xls,包括4个sheet,分别存放DEPT A00,DEPT B01,DEPT C01,DEPT D01这四个部门的员工信息;并且,这4个sheet的数据结构一致,每个sheet的第3行都表示字段名。数据样本如下:
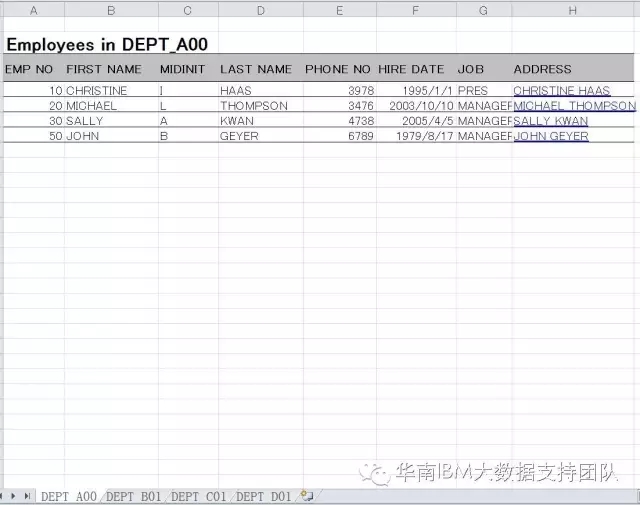
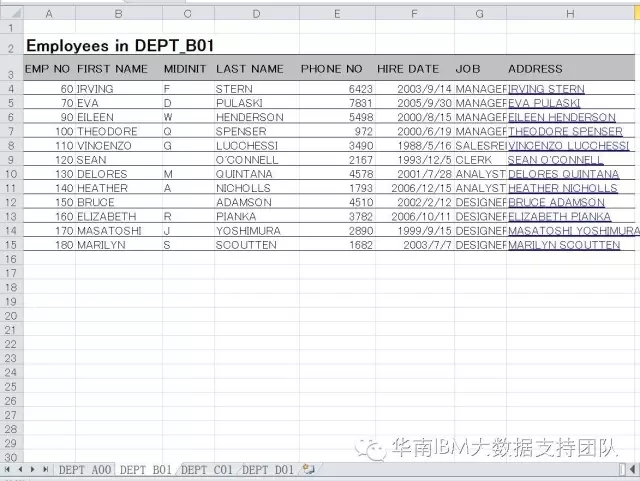
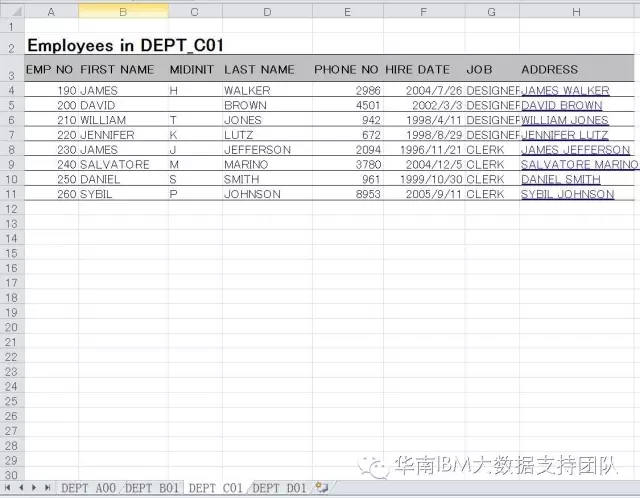
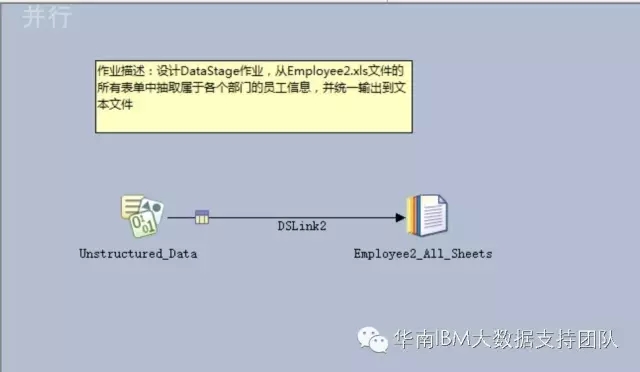
2. 设计DataStage作业,从Employee2.xls文件的所有表单中抽取属于各个部门的员工信息,并统一输出到文本文件。
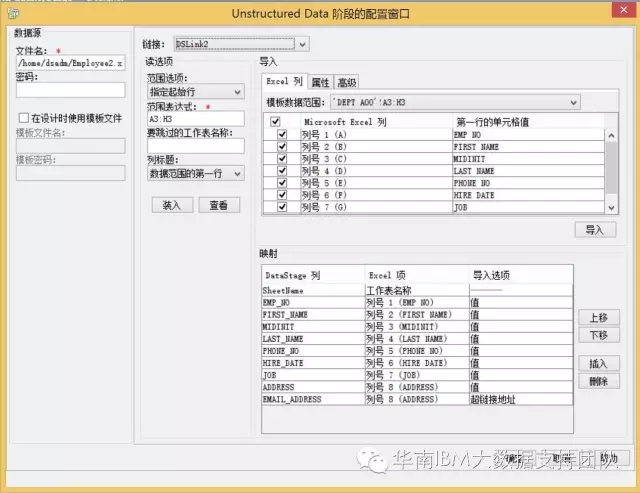
- 文件名:Excel源文件的文件名及目录路径;
- 范围选项:指定起始行,表示从下面的范围表达式中读取起始行以下的所有记录;
- 范围表达式:指定起始行的具体位置,即A3:H3;因为没有指定sheet名,所以遍历所有sheet;
- 列标题:数据范围的第一行,表示第一行为字段名,所以从第二行开始抽取数据;
- 映射:新增字段,在输出结果中新增两个字段“SheetName”和“EMAIL_ADDRESS”,分别表示工作表单名称和邮件地址;
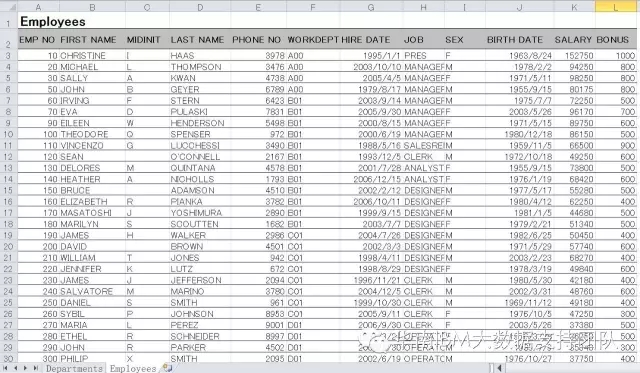
3. 编译并运行作业,结果数据如下:

场景三:对Excel文件中的多个sheet分别进行数据抽取
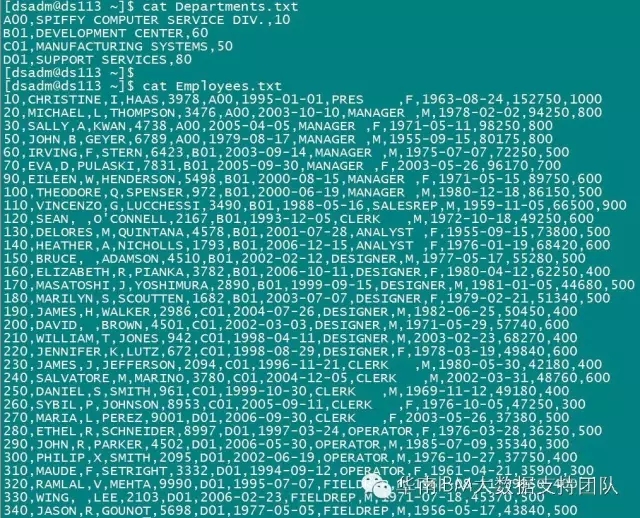
1. Excel文件名为Employee3.xls,包括2个sheet(Departments,Employees),分别存放部门信息和员工信息;并且,这2个sheet的数据结构不一致。数据样本如下:

2. 设计DataStage作业,从Employee3.xls文件的多个表单中分别抽取部门信息和员工信息,输出到不同的文本文件。
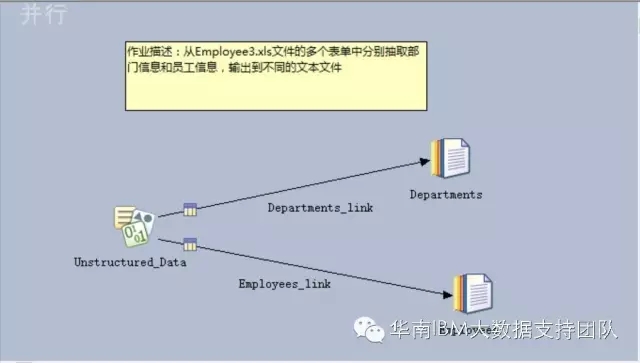
- 文件名:Excel源文件的文件名及目录路径;
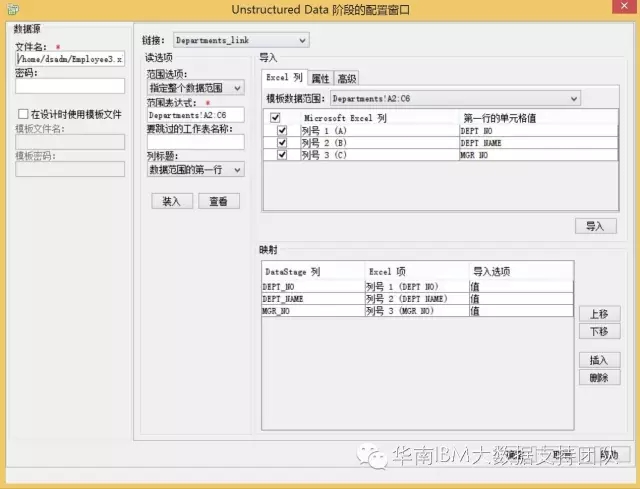
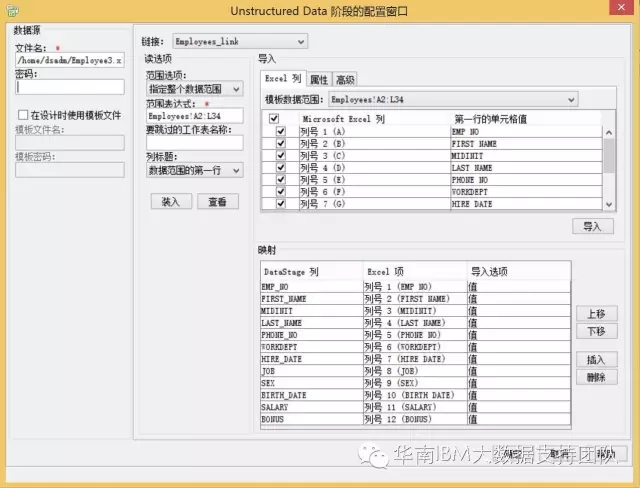
- 范围选项:指定整个数据范围,表示从下面的范围表达式中读取数据;
- 范围表达式:指定读取数据的具体范围,即Departments表单的A2:C6以及Employees表单的A2:L34;
- 列标题:数据范围的第一行,表示第一行为字段名,所以从第二行开始抽取数据;
3. 编译并运行作业,结果数据如下
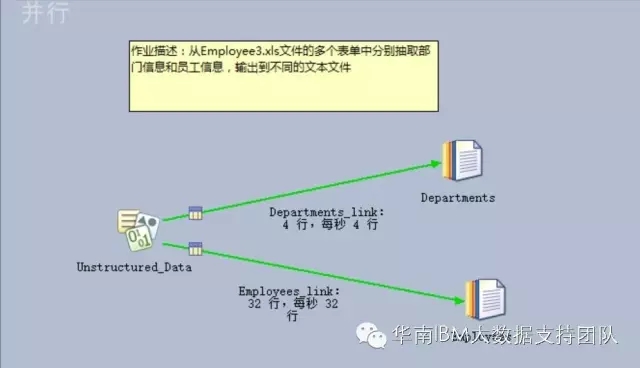
总结:
InfoSphere DataStage不仅能灵活解析并读取Excel多表单文件,而且还能实现创建或写入Excel文件,更能支持多种类型的非结构化数据,
想要了解更多有关DataStage的功能和数据集成场景吗,请访问下面链接:http://bigdata.evget.com/products-16-1.html
via:华南IBM大数据支持团队
更多大数据与分析相关行业资讯、解决方案、案例、教程等请点击查看>>>
详情请咨询“在线客服”!
客服热线:023-66090381


