1. 决定目标:在获取数据之前,数据价值链的第一步要先决定目标:业务部门要决定数据科学团队的目标。这些目标通常需要进行大量的数据收集和分析。因为我们正在研究那些驱动决策的数据,所以需要一个可衡量的方式,判断业务是否正向着目标前进。数据分析过程中,关键权值或性能指标必须及早发现。

2. 确定业务手段:应该通过业务的改变,来提高关键指标和达到业务目标。如果没有什么可以改变的,无论收集和分析多少数据都不可能有进步。在项目中尽早确定目标、指标和业务手段能为项目指明方向,避免无意义的数据分析。例如,目标是提高客户滞留度,其中一个指标可以是客户更新他们订阅的百分比,业务手段可以是更新页面的设计,提醒邮件的时间和内容以及特别的促销活动。

3. 数据收集:数据收集要尽量广撒网。更多的数据—-特别是更多的不同来源的数据—-使得数据科学家能找到数据之间更好的相关性,建立更好的模型,找到更多的可行性见解。大数据经济意味着个人记录往往是无用的,拥有可供分析的每一条记录才能提供真正的价值。公司通过检测它们的网站来密切跟踪用户的点击及鼠标移动,商店通过在产品上附加RFID来跟踪用户的移动,教练通过在运动员身上附加传感器来跟踪他们的行动方式。

4. 数据清洗:数据分析的第一步是提高数据质量。数据科学家要纠正拼写错误,处理缺失数据以及清除无意义的信息。这是数据价值链中最关键的步骤。垃圾数据,即使是通过最好的分析,也将产生错误的结果,并误导业务本身。不止一个公司很惊讶地发现,他们很大一部分客户住在纽约的斯克内克塔迪,而该小镇的人口不到70000人。然而,斯克内克塔迪的邮政编码是12345,由于客户往往不愿将他们的真实信息填入在线表单,所以这个邮政编码会不成比例地出现在几乎每一个客户的档案数据库中。直接分析这些数据将导致错误的结论,除非数据分析师采取措施来验证和清洗数据。尤为重要的是,这一步将规模化执行,因为连续数据价值链要求传入的数据会立即被清洗,且清洗频率非常高。这通常意味着此过程将自动执行,但这并不意味着人无法参与其中。
5. 数据建模:数据科学家构建模型,关联数据与业务成果,提出关于在第一步中确定的业务手段变化的建议。数据科学家独一无二的专业知识是业务成功的关键所在,就体现在这一步—-关联数据,建立模型,预测业务成果。数据科学家必须有良好的统计学和机器学习背景,才能构建出科学、精确的模型,避免毫无意义的相关性及一些模型的陷阱。这些模型依赖于现有的数据,但对于未来的预测是无用的。但只有统计学背景是不够的,数据科学家还需要很好地了解业务,这样他们才能判断数学模型的结果是否有意义,以及是否具有相关性。
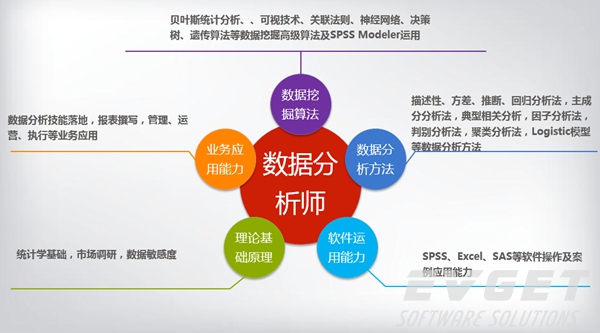
6. 培养一个数据科学团队:数据科学家是出了名的难雇用,所以最好自己构建一个数据科学团队,让团队中那些在统计学方面有高级学位的人专注于数据建模和预测,而其他人—-合格的基础架构工程师,软件开发人员和ETL专家—-构建必要的数据收集基础设施,数据管道和数据产品,使得结果数据能够从模型中输出,并以报告和表格的形式在业务中进行展示。这些团队通常使用类似Hadoop的大规模数据分析平台自动化数据收集和分析工作,并作为一个产品运行整个过程。

7. 优化和重复:数据价值链是一个可重复的过程,能够对业务和数据价值链本身产生连续的改进。基于模型的结果,业务将根据驱动手段做出改变,数据科学团队将评估结果。在结果的基础上,企业可以决定下一步计划,而数据科学团队继续进行数据收集、数据清理和数据建模。企业重复这个过程越快,就会越早修正发展方向,越快得到数据价值。理想情况下,多次迭代后,模型将产生准确的预测,业务将达到预定的目标,结果数据价值链将用于监测和报告,同时团队中的每个人将开始解决下一个业务挑战。
英文出处:analyticsweek
转载自:伯乐在线
慧都年终盛典火爆开启,一年仅一次的最强促销,破冰钜惠不容错过!!优惠详情点击查看>>


